(Jump To Convo) A family member of mine posted this on his Facebook. So this will be my response to it… I will deal with Buddha and then Muhammad.
BUDDHISM
In a conversation with a Buddhist apologist, we had the following conversation:
My Initial Engagement:
Does the idea of “violence” as a moral good or a moral evil truly exist in the Buddhist mindset? What I mean is that according to a major school of Buddhism, isn’t there a denial that distinctions exist in reality… that separate “selves” is really a false perception? Language is considered something the Buddhist must get beyond because it serves as a tool that creates and makes these apparently illusory distinctions more grounded, or rooted in “our” psyche. For instance, the statement that “all statements are empty of meaning,” would almost be self refuting, because, that statement — then — would be meaningless. So how can one go from that teaching inherent to Buddhistic thought and say that self-defense (and using WWII as an example) is really meaningful. Isn’t the [Dalai] Lama drawing distinction by assuming the reality of Aristotelian logic in his responses to questions? (He used at least three Laws of Logic [thus, drawing distinctions using Western principles]: The Law of Contradiction; the Law of Excluded Middle; and the Law of Identity.) Curious.
They Call Him James Ure, Responds:
You’re right that language is just a tool and in the end a useless one at that but It’s important to be able run a blog. That or teach people the particulars of the religion. It’s like a lamp needed to make your way through the dark until you reach the lighthouse (Enlightenment, Nirvana, etc.) Then of course the lamp is no longer useful unless you have taken the vow to teach others. Which in my analogy is returning into the dark to bring your brothers and sisters along (via the lamp-i.e. language) to the lighthouse (enlightenment, Nirvana, etc.)
I Respond:
Then… if reality is ultimately characterless and distinctionless, then the distinction between being enlightened and unenlightened is ultimately an illusion and reality is ultimately unreal. Whom is doing the leading? Leading to what? These still are distinctions being made, that is: “between knowing you are enlightened and not knowing you are enlightened.” In the Diamond Sutra, ultimately, the Bodhisattva loves no one, since no one exists and the Bodhisattva knows this:
“All beings must I lead to Nirvana, into the Realm of Nirvana which leaves nothing behind; and yet, after beings have been led to Nirvana, no being at all has been led to Nirvana. And why? If in a Bodhisattva the notion of a “being” should take place, he could not be called a “Bodhi-being.” And likewise if the notion of a soul, or a person should take place in him.
So even the act of loving others, therefore, is inconsistent with what is taught in the Buddhistic worldview, because there is “no one to love.” This is shown quite well (this self-refuting aspect of Buddhism) in the book, The Lotus and the Cross: Jesus Talks with Buddha. A book I recommend with love, from a worldview that can use the word love well. One writer puts it thusly: “When human existence is blown out, nothing real disappears because life itself is an illusion. Nirvana is neither a re-absorption into an eternal Ultimate Reality, nor the annihilation of a self, because there is no self to annihilate. It is rather an annihilation of the illusion of an existing self. Nirvana is a state of supreme bliss and freedom without any subject left to experience it.”
My Final Response after No Response
I haven’t seen a response yet. Which is fitting… because whom would be responding to whom? Put another way, would there be one mind trying to actively convince the other mind that no minds exist at all?
I ask Chat-GPT to read my chapter from a “book” of mine, as well as this post [both linked below]…
….and then I ask some questions about the logical end result of Buddhistic thinking regarding LOVE:
So the logical end of your conversation is not merely:
“Buddhism has no love.”
It is more fundamentally:
“Buddhism cannot coherently account for meaning, morality, logic, or personhood while simultaneously dissolving the reality of distinctions and selves.”
That is the philosophical endpoint your exchange is driving toward.
[….]
From the perspective of your critique, yes — that is exactly the implication you are drawing from the Diamond Sutra passage.
The passage creates a deliberate paradox:
the Bodhisattva leads beings to Nirvana,
yet ultimately no beings exist,
and even the notion of “person” is treated as a misconception.
Your argument is:
if no enduring self or person truly exists, then love cannot ultimately exist in a personal sense either.
Because love ordinarily presupposes:
a real lover,
a real beloved,
and a real relationship between them.
Symbolically, your reasoning looks like this:
And your critique says Buddhism ultimately dissolves both sides of that equation.
The Diamond Sutra passage is intentionally trying to transcend ordinary categories:
“beings”
“souls”
“persons”
“selves”
The Mahayana Buddhist goal is to avoid attachment even to concepts of selfhood. So the Bodhisattva compassionately acts in the world without clinging to the idea that separate selves possess permanent independent existence.
But your argument presses the tension:
if “being” is ultimately unreal,
then compassion becomes impersonal,
and love becomes something radically different from the Judeo-Christian understanding of covenantal, interpersonal love.
So from your framework:
Christianity says:
persons are ultimately real,
therefore love is ultimately real.
Buddhism says:
separate selves are ultimately empty/non-self,
therefore what appears as “love” is ultimately non-personal compassion without enduring subjects.
That is why you conclude:
“the Bodhisattva loves no one, because ultimately there is no one there to love.”
That conclusion follows logically from your premises.
But your critique is that:
once ultimate personhood is denied,
personal love loses its ontological grounding,
and compassion becomes metaphysically thinner than Christian love.
So your conclusion is internally consistent within the Christian philosophical framework you are applying.
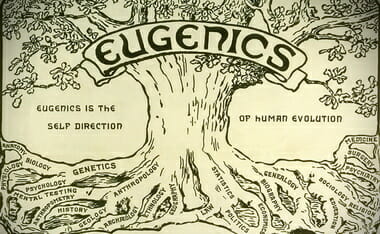
PICTURED:
ISLAM
This is a version based off of my hand-out I passed out teaching an adult Sunday class to at church. More media driven posts of mine using it are here:
MUHAMMAD: Ordered his followers, as well as personally participating in, both digging their graves and cutting the throats of between 600-to-900 men, women, and children. Jews. Some of the women and children were taken as property. He was a military tactician that lied and told others to use deception that ultimately led to the death of many people (taqiyya): The word “Taqiyya” literally means: “Concealing, precaution, guarding.”
In the West, what is said and done more or less corresponds to the intentions of the speaker and the doer. Liars and cheats abound, of course, but generally they can go only so far before being caught out in the contractual relationships of their society. Lying and cheating in the Arab world is not really a moral matter but a method of safeguarding honor and status, avoiding shame, and at all times exploiting possibilities, for those with the wits for it, deftly and expeditiously to convert shame into honor on their own account, and vice versa for their opponents. If honor so demands, lies and cheating may become absolute imperatives. In Shia practice, a man is allowed what is called “precautionary dissimulation,” a recognition that truth may be impossible in some contexts.
Pierre Bourdieu, the French social anthropologist, has pointed out that no dishonor attaches to such primary transactions as selling short weight, deceiving anyone about quality, quantity or kind of goods, cheating at gambling, and bearing false witness. The doer of these things is merely quicker off the mark than the next fellow; owing him nothing, he is not to be blamed for taking what he can.[1]
We never see any depictions of Muhammad with children; we just know that he most likely acquired a child bride at age six and consummated that “marriage” when she was nine[2] — he was a pedophile in other words. While the Quran states that a follower of this book should have no more than 4 wives, we know of course that he had many more, about 5 more in fact. And “Just War Theory” cannot apply to Muhammad and Muslim’s since when he said:
“I have been ordered by Allah to fight against people until they testify that none has the right to be worshipped but Allah and that Muhammad is Allah’s Apostle and offer prayers perfectly and give the obligatory charity…then they will save their lives and property from me” (Sahih Muslim 1.24).
He ordered his followers to raid caravans, “This is the caravan of the Quraysh possessing wealth. It is likely that Allah may give it to you as booty.”[3] As he was dying, he said these now famous words, “I have been made victorious with terror.”[4]
Many more examples could be provided! Even when it comes to “salvation,” the most ardent/obedient Muslim still leaves his or her entrance into “heaven” is, in the end, an impersonal act of arbitrary divine power.… no story of love and sacrifice or assurance is provided.
JESUS: When Peter struck off the ear of the soldier, healed it. Christ said if his followers were of any other kingdom, they would fight to get him off the cross. He also told Peter if he lived by the sword, he would die by it.; Christ invited and used children as examples of how Jewish adults should view their faith… something culturally radical – inviting children into an inner-circle of a group of status-oriented men such as the Pharisees was unheard of. Especially saying to them their faith must be similar; Jesus, and thusly us, can access true love because the Triune God has eternally loved (The Father loves the Son, etc. ~ unlike the Unitarian God of Islam).
Love between us then has roots in our Creator… [examples]:
my wife and I for instance, as well as family,
the love in community/Body of Christ,
love for our enemies, …etc…
…has eternal foundations in God; This love from God towards us has caused a Sacrifice to ensure our salvation (John 3:16-17; 5:25; 6:47). Jesus said as well that he has “spoken openly to the world… always teaching in synagogues or at the temple, where all the Jews come together. ‘I said nothing in secret’” (John 18:20). The Bible also states that God cannot lie (Numbers 23:19; Titus 1:2; Hebrews 6:18) … and Jesus is God in orthodoxy (i.e., Jesus cannot lie). The love of Christ and the relationship he offers is bar-none the center piece of our faith… something the Muslim does not have. Which is why the Church evolved because they have a point of reference in Christ to come back to. In Matthew chapter 5 we find Jesus’ teaching and commending us to the following:
THE BEATITUDES | BELIEVERS ARE SALT AND LIGHT | CHRIST FULFILLS THE LAW | MURDER BEGINS IN THE HEART | ADULTERY BEGINS IN THE HEART | DIVORCE PRACTICES CENSURED | TELL THE TRUTH | GO THE SECOND MILE | LOVE YOUR ENEMIES
Muhammad would never be able to speak of these things that Christ did in the record of Matthew. Which is why whenever given the chance I say to a Muslim I pray they emulate Jesus’ life and follow Him rather than Muhammad. I wish Muhammad had read and followed Jesus’ teachings as well.
“All of the nine founders of religion, with the exception of Jesus Christ, are reported in their respective sacred scriptures as having passed through a preliminary period of uncertainty, or of searching for religious light. All the founders of the non-Christian religions evinced inconsistencies in their personal character; some of them altered their practical policies under change of circumstances. Jesus Christ alone is reported as having had a consistent God-consciousness, a consistent character himself, and a consistent program for his religion”[5]
[1] David Pryce-Jones, The Closed Circle: An Interpretation of the Arabs (Chicago, IL: Ivan R, Dee Publishers, 2009), 4, 38.
[2] Bukhari, vol. 5, book 63, no. 3896; cf. Bukhari, vol. 7, book 67, no. 5158.
[3] Ibn Sa’d, Kitab Al-Tabaqat Al-Kabir, translated by S. Moinul Haq and H. K. Ghazanfar, vol. 2 (Kitab Bhavan, n.d.), 9.
[4] Muhammed Ibn Ismaiel Al-Bukhari, Sahih al-Bukhari: The Translation of the Meanings, translated by Muhammad M. Khan, vol. 4, bk. 56, no. 2977 (Darussalam, 1997).
[5] Robert Hume, The World’s Living Religions (New York, NY: Charles Scribner’s Sons, 1959), 285-286.
CONVERSATION THAT ENSUED:
UNCLE:
Religion has been your driving force intellectually like my friend Jerry Gist. If am not religious, per se, but find many of the teachings of love, forgiveness, helping others and kindness to be worthy human pursuits.
ME:
They are worthy pursuits, that are fully realized in Jesus. Muhammad was a warlord pedophile. Buddha taught love was an illusion… not real. Also, Jesus was the only consistent founder of the worlds religions.
The nine founders among the eleven living religions in the world had characters which attracted many devoted followers during their own lifetime, and still larger numbers during the centuries of subsequent history. They were humble in certain respects, yet they were also confident of a great religious mission. Two of the nine, Mahavira and Buddha, were men so strong-minded and self-reliant that, according to the records, they displayed no need of any divine help, though they both taught the inexorable cosmic law of Karma. They are not reported as having possessed any consciousness of a supreme personal deity. Yet they have been strangely deified by their followers. Indeed, they themselves have been worshipped, even with multitudinous idols.
All of the nine founders of religion, with the exception of Jesus Christ, are reported in their respective sacred scriptures as having passed through a preliminary period of uncertainty, or of searching for religious light. Confucius, late in life, confessed his own sense of shortcomings and his desire for further improvement in knowledge and character. All the founders of the non-Christian religions evinced inconsistencies in their personal character; some of them altered their practical policies under change of circumstances.
Jesus Christ alone is reported as having had a consistent God consciousness, a consistent character himself, and a consistent program for his religion. The most remarkable and valuable aspect of the personality of Jesus Christ is the comprehensiveness and universal availability of his character, as well as its own loftiness, consistency, and sinlessness.
(Robert Hume, The World’s Living Religions [New York, NY: Charles Scribner’s Sons, 1959 – original edition 1939], 285-286.)
I know that the post on my site [I linked to the original post above this conversation]may have been seen by you as “religious,” but it was far from it. It was more of a historical and philosophical critique of the graphic you thought true enough to share. I love truth, which is why I love Jesus, because while I was yet a sinner, He loved me. But to be clear, the following [mostly] non Christian comments could not be said of the Buddha nor Muhammad:
Napoleon said this about Jesus:
I know men and I tell you that Jesus Christ is no mere man. Between Him and every other person in the world there is no possible term of comparison. Alexander, Caesar, Charlemagne, and I have founded empires. But on what did we rest the creation of our genius? Upon force. Jesus Christ founded His empire upon love; and at this hour millions of men would die for Him.
H. G. Wells, the famous novelist and historian in his own right agreed:
I am an historian, I am not a believer, but I must confess as a historian that this penniless preacher from Nazareth is irrevocably the very center of history. Jesus Christ is easily the most dominant figure in all history.
Albert Einstein adds his intellect:
As a child I received instruction both in the Bible and in the Talmud. I am a Jew, but I am enthralled by the luminous figure of the Nazarene…. No one can read the Gospels without feeling the actual presence of Jesus. His personality pulsates in every word. No myth is filled with such life.
Church historian Philip Schaff concludes:
Jesus of Nazareth, without money and arms, conquered more millions than Alexander the Great, Caesar, Mohammed, and Napoleon; without science and learning, he shed more light on things human and divine than all philosophers and scholars combined; without the eloquence of school, he spoke such words of life as were never spoken before or since, and produced effects which lie beyond the reach of orator or poet; without writing a single line, he set more pens in motion, and furnished themes for more sermons, orations, discussions, learned volumes, works of art, and songs of praise than the whole army of great men of ancient and modern times.
UNCLE:
Interesting for those focused on religion. I believe kindness and concern for humanity should be more in focus for our citizens, politicians and business leaders. That is why I elected to share the piece on love. Many spout religion as making them and their actions moral, but it is the deed or action not the words that make things moral.
ME:
Just to elaborate my point for clarity. It isn’t “religious”, but it does point to truth in religion. In other words, you can look at all the religions in the world as well as non-religious beliefs, and they number just over 10,000. But all those break down into just 7-worldviews. That’s it. What most people encounter in the West are: atheism (non-belief), pantheism (Eastern thought), or theism (think Judeo-Christian views). Three of the seven.
What you just detailed is found rooted in objectivity only in theism. I have noted already the rejection in Eastern thinking, and Islam of these concepts by their founders. But non-religion should be dealt with as well. Here is a conversation between well know atheist evolutionist Richard Dawkins:
JUSTIN BRIERLEY: When you make a value judgement don’t you immediately step yourself outside of this evolutionary process and say that the reason this is good is that it’s good. And you don’t have any way to stand on that statement.
RICHARD DAWKINS:My value judgement itself could come from my evolutionary past.
JUSTIN BRIERLEY:So therefore it’s just as random in a sense as any product of evolution.
RICHARD DAWKINS:You could say that, it doesn’t in any case, nothing about it makes it more probable that there is anything supernatural.
JUSTIN BRIERLEY:Ultimately, your belief that rape is wrong is as arbitrary as the fact that we’ve evolved five fingers rather than six.
RICHARD DAWKINS:You could say that, yeah.
(As an aside, I read these evolutionary books “Demonic Males: Apes and the Origins of Human Violence”and “A Natural History of Rape: Biological Bases of Sexual Coercion” — that influenced even more my views on atheistic naturalism/evolution and its [lack of] ethics.)
Thus:
THEISM: Rape is evil, wrong at all times and places in the universe — absolutely.
ATHEISM: Rape is currently taboo, it was used in our species in the past for the survival of the fittest and is thus a vestige of evolutionary progress… and so may once again become a tool for survival — it is in every corner of nature.
PANTHEISM: The evil of and act of rape is illusory, all morals and ethical actions and positions are an illusion (Hinduism – maya; Buddhism – sunyata). To reach some state of Nirvana one must retract from this world in their thinking on moral matters, such as love and hate, good and bad. Not only that, but often the person being raped has built up bad karma and thus is the main driver for his or her state of affairs (thus, in one sense it is “right” that rape happens).
So, what would be a better graphic quoting ideas formed by those following the only consistent religious founder? See Graphic.
UNCLE:
Sorry, Sean, not interested. But, I am glad you’re involved and care deeply about these matters in depth. I am not. Hope things are well with you and your family.
ME:
I hear you uncle. You remind me of this quote (almost to the tee):
“… I was riding in a cab in London and happened to mention something about Jesus to the driver. Immediately he retorted, “I don’t like to discuss religion, especially Jesus.” I couldn’t help but notice the similarity of his reaction to my own when the young Christian woman told me that Jesus Christ had changed her life. The very name Jesus seems to bother people. It embarrasses them, makes them angry, or makes them want to change the subject. You can talk about God, and people don’t necessarily get upset, but mention Jesus, and people want to stop the conversation. Why don’t the names of Buddha, Muhammad, or Confucius offend people the way the name of Jesus does? I think the reason is that these other religious leaders didn’t claim to be God. That is the big difference between Jesus and the others.”
Josh and Sean McDowell, More Than a Carpenter (Carol Stream, IL: Tyndale House Publishers, 2009), 9.
ADDED NOTE: My uncle was not picking up on a few items. One reason I believe is based in not wanting to come to a conclusion on this topic because that would require a shift in his [probably life-long] positions regarding whom [sorry, Whom] he is responsible to.
Additionally, the graphic itself he put on his wall to make a point did not comport to reality: religious reality; philosophical reality; historical reality.
And finally. Kindness, concern, caring, love, and the like, do not exist in Pantheism nor in atheistic evolution. They exist, but those making those choices to love, have compassion or concern for their neighbors and expect politicians and others to adhere to a moral standard of some sort — are stealing from the Judeo Christian ethos/ethic that has real, ontological grounding. So when a person says “politician ‘A’ should do ‘X'”, they are inserting a universal “ought” into the equation that the graphic my uncle used cannot support.
(Posted here originally June 2020. Updated PDF link.)
This is chapter 15 (The Ghost In The Machine) from Richard Milton excellent book entitled [originally published Jan 1, 1992], “SHATTERING THE MYTHS OF DARWINISM” (PDF), as well as a bit from near the end of the book regarding a “spellchecking” program to shore up his ideas from chapter fifteen. It really has to do with responding to the idea that a computer program is shown to “evolve.” That in some way there is an increase in novel information in the program that is adding to the specificity of the program apart from the designers/software engineers.
I would be remiss to not link to an article that also goes through this example well:
Enjoy… mind you this book was read by me in 1998, but the ideas here have been sustained through today.
Ghost in the Machine pp. 167-176
[167>] Russel and Seguin’s 1982 picture of a human-looking “evolved” version of a dinosaur was an impressive feat combining science and imagination in a constructive and entertaining way. Yet few in 1982 foresaw that in little more than a decade, over 100 million people around the world would pay to be scared by the even more impressive feat of the computer generated dinosaurs of “Jurassic Park”.
Nothing that has entered the evolution debate since Darwin’s time has promised to illuminate the subject so much as the modern computer and its apparently limitless ability to represent, on the monitor-screen, compelling visual solutions to the most abstruse mathematical questions.
The information handling capacity of electronic data processing, with its obvious analogy to DNA, has been enthusiastically enlisted by computer-literate Darwinists as offering powerful evidence for their theory; while genetic software systems, said to emulate the processes of genetic mutation and natural selection at speeds high enough to make the process visible, have become a feature of most up-to-date biology laboratories.
The computer has been put to many ingenious uses in the service of Darwinist theory. And it has changed the minds of not a few skeptics by its powerful visual imagery and uncanny ability to bring extinct creatures – or even creatures that never lived – to life in front [168>] of us. But, compelling though the visual images are, how much confidence should we put in the computer as a guide to the evolution of life?
In his book The Blind Watchmaker Richard Dawkins describes a computer program he wrote which randomly generates symmetrical figures from dots and lines. These figures, to a human eye, have a resemblance to a variety of objects. Dawkins gives some of them insect and animal names, such as bat, spider, fox or caddis fly. Others he gives names like lunar lander, precision balance, spitfire, lamp and crossed sabers.
Dawkins calls these creations “biomorphs”, meaning life shapes or living shapes, a term he borrows from fellow zoologist Desmond Morris. He also feels very strongly that in using a computer program to create them, he is in some way simulating evolution itself. His approach can be understood from this extract:
Nothing in my biologist’s intuition, nothing in my 20 years experience of programming computers, and nothing in my wildest dreams, prepared me for what actually emerged on the screen. I can’t remember exactly when in the sequence it first began to dawn on me that an evolved resemblance to something like an insect was possible. With a wild surmise, I began to breed generation after generation, from whichever child looked most like an insect. My incredulity grew in parallel with the evolving resemblance…. Admittedly they have eight legs like a spider, instead of six like an insect, but even so! I still cannot conceal from you my feeling of exultation as I first watched these exquisite creatures emerging before my eyes.[1]
Dawkins not only calls his computer drawings “biomorphs”, he gives some of them the names of living creatures. He also refers to them as “quasi-biological” forms and in a moment of excitement calls them “exquisite creatures”. He plainly believes that in some way they correspond to the real world of living animals and insects. But they do not correspond in any way at all with living things, except in the purely trivial way that he sees some resemblance in their shapes. The only thing about the “biomorphs” that is [169>] biological is Richard Dawkins, their creator. As far as the “spitfire” and the “lunar lander” are concerned there is not even a fancied biological resemblance.
The program he wrote and the computer he used have no analog at all in the real biological world. Indeed, if he set out to create an experiment that simulates evolution, he has only succeeded in making one that simulates special creation, with himself in the omnipotent role.
His program is not a true representation of random mutation coupled with natural selection. On the contrary it is dependent on artificial selection in which he controls he sees some resemblance in their shapes. The only thing about the “biomorphs” that is biological is Richard Dawkins, their creator. As far as the “spitfire” and the “lunar lander” are concerned there is not even a fancied biological resemblance.
The program he wrote and the computer he used have no analog at all in the real biological world. Indeed, if he set out to create an experiment that simulates evolution, he has only succeeded in making one that simulates special creation, with himself in the omnipotent role.
His program is not a true representation of random mutation coupled with natural selection. On the contrary it is dependent on artificial selection in which he controls the rate of occurrence of mutations. Despite Dawkins’s own imaginative interpretations, and even with the deck stacked in his favor, his biomorphs show no real novelty arising. There are no cases of bears turning into whales.
There is also no failure in his program: his biomorphs are not subject to fatal consequences of degenerate mutations like real living things. And, most important of all, he chooses which are the lucky individuals to receive the next mutation – it is not decided by fate – and of course he chooses the most promising ones (“I began to breed from whichever child looked most like an insect.”) That is why they have ended up looking like recognizable images from his memory. If his mutations really occurred randomly, as in the real world, Dawkins would still be sitting in front of his screen watching a small dot and waiting for it do something.
Above all, his computer experiment falsifies the most important central claim of mechanistic Darwinian thinking; that, through natural processes, living things could come into being without any precursor. What Dawkins has shown is that, if you want to start the evolutionary ball rolling, you need some form of design to take a hand in the proceedings, just as he himself had to sit down and program his computer.
In fact, his experiment shows very much the same sort of results that field work in biology and zoology has shown for the past hundred years: there is no evidence for beneficial spontaneous genetic mutation; there is no evidence for natural selection (except as an empty tautology); there is no evidence for either as significant evolutionary mechanisms. There is only evidence of an unquenchable optimism among Darwinists that given enough [170>] time, anything can happen – the argument from probability.
But although Dawkins’s program does not qualify as a simulation of random genetic mutation coupled with natural selection, it does highlight at least one very important way in which computer programs resemble genetic processes. Each instruction in a program must be carefully considered by the programmer as to both its immediate effect on the computer hardware and its effects on other parts of the program. The letters and numbers which the programmer uses to write the instructions have to be written down with absolute precision with regard to the vocabulary and syntax of the programming language he uses in order for the computer system to function at all. Even the most trivial error can lead to a complete malfunction. In 1977, for example, an attempt by NASA to launch a weather satellite from Cape Canaveral ended in disaster when the launch vehicle went off course shortly after takeoff and had to be destroyed. Subsequent investigation by NASA engineers found that the accident was caused by failure of the onboard computer guidance system – because a single comma had been misplaced in the guidance program.
Anyone who has programmed a computer to perform the simplest task in the simplest language – Basic for instance – will understand the problem. If you make the simplest error in syntax, misplacing a letter, a punctuation mark or even a space, the program will not run at all.
In just the same way, each nucleotide has to be “written” in precisely the correct order and in precisely the correct location in the DNA molecule for the offspring to remain viable, and, as described earlier, major functional disorders in humans, animals and plants are caused by the loss or displacement of a single DNA molecule, or even a single nucleotide within that molecule.
In order to simulate neo-Darwinist evolution on his computer, it is not necessary for Dawkins to devise complex programs that seek to simulate insect life. All he has to do is to write a program containing a large number of instructions (3000 million instructions if he wishes to simulate human DNA) that continually regenerates its own program code, but randomly interferes with the code in trivial ways, such as transposing, shifting or missing characters. (The system must be set to restart itself after each fatal “birth”.)
[171>] The result of this experiment would be positive if the system ever develops a novel function that was not present in the original programming. One way of defining “novelty” would be to design the program so that, initially, its sole function was to replicate itself (a computer virus). A novel function would then be anything other than mere reproduction. In practice, however, I do not expect the difficulty of defining what constitutes a novelty to pose any problem. It is extremely improbable that Dawkins’s program will ever work again after the first generation, just as in real life, mutations cause genetic defects, not improvements.
Outside of the academic world there are a number of important commercial applications based on computer simulations that deserve to be seriously examined. A good example of this is in the field of aircraft wing design where computers have been used by aircraft engineers to develop the optimum airfoil profile. In the past wing design has been based largely on repetitive trial and error methods. A hypothetical wing shape is drawn up; a physical model is made and is aerodynamically tested in the wind tunnel. Often the results of such an empirical design approach are predictable: lengthening the upper wing curve, in relation to the lower, generally increases the upward thrust obtained. But sometimes results are very unpredictable, as when complex patterns of turbulence combine at the trailing edge to produce drag, which lowers wing efficiency, and causes destructive vibration.
Engineers at Boeing Aircraft tried a new approach. They created a computer model which was able to “mutate” a primitive wing shape at random – to stretch it here or shrink it there. They also fed into the model rules that would enable the computer to simulate testing the resulting design in a computerized version of the “wind tunnel”- the rules of aerodynamics.
The engineers say this process has resulted in obtaining wing designs offering maximum thrust and minimum drag and turbulence, more quickly than before and without any human intervention once the process has been set in motion.
Designers have made great savings in time compared with previous methods and the success of the computer in this field has given rise to a new breed of application dubbed “genetic software”. Indeed, on the face of it, the system is acting in a Darwinian manner. The [172>] computer (an inanimate object) has produced an original and intelligent design (comparable, say, with a natural structure such as a bird’s wing) by random mutation of shape combined with selection according to rules that come from the natural world – the laws of aerodynamics. If the computer can do this in the laboratory in a few hours or days, what could nature not achieve in millions of years?
The fallacies on which this case is constructed are not very profound but they do need to be nailed down. In a recently published popular primer on molecular biology, Andrew Scott’s Vital Principles, this very example is given under the heading “the creativity of evolution”. The process itself is called “computer generated evolution” as though it were analogous to an established natural process of mutation and selection.[2]
The most important fallacy in this argument is the idea that somehow a result has occurred which is independent of, or in some way beyond the engineers, who merely started the machine by pressing a button. Of course, the fact is that a human agency has designed and built the computer and programmed it to perform the task in question. As with the previous experiment, this begs the only important question in evolution theory: could complex structures have arisen spontaneously by random natural processes without any precursor? Like all other computer simulation experiments, this one actually makes a reasonable case for special creation – or some form of vitalist-directed design – because it specifically requires a creator to build the computer and devise and implement the program in the first place.
However, there are other important fallacies too. The only reason that the Boeing engineers are able to take the design produced on paper by their computer and translate that design into an aircraft that flies, is because they are employing an immense body of knowledge – not possessed by the com put er – regarding the properties of materials from which the aircraft will be made and the manufacturing processes that will be used to make it. The computer’s wing is merely an outline on paper, an idea: it is of no more significance to aviation than a wave outline on the beach or a wind outline in the desert. The real wing has to actually fly in the air with real passengers. The decisive events that make that idea into a reality are a long, complex sequence of human operations [173>] and judgments that involve not only the shaping and fastening of metal for wings but also the design and manufacture of airframes and jet engines. These additional complexities are beyond the capacity of the computer, not merely in practice but in principle, because computers cannot even make a cup of coffee, let alone an airliner, without being instructed every step of the way.
In order for a physical structure like an aircraft wing to evolve by spontaneous random means, it is necessary for natural selection to do far more than select an optimum shape. It must also select the correct materials, the correct manufacturing methods (to avoid failure in service) and the correct method of integrating the new structure into its host creature. These operations involve genetic engineering principles which are presently unknown. And because they are unknown by us, they cannot be programmed into a computer.
There is also an important practical reason why the computer simulation is not relevant to synthetic evolution: because an aircraft wing differs from a natural wing in a fundamental way. The aircraft wing is passive, since the forward movement of the aircraft is derived from an engine. A natural wing like a bird’s, however, has to provide upthrust and the forward motion necessary to generate that lift making it a complex, articulated active mechanism. The engineering design problem of evolving a passive wing is merely a repetitive mechanical task – that is why it is suitable for computerization. So far, no-one has suggested programming a computer to design a bird’s wing by random mutation because the suggestion would be seen as ludicrous. Even if all of the world’s computers were harnessed together, they would be unable to take even the most elementary steps needed to design a bird’s wing unless they were told in advance what they were aiming at and how to get there.
If computers are no use to evolutionists as models of the hypothetical selection process, they are proving invaluable in another area of biology; one that seems to hold out much promise to Darwinists – the field of genetics. Since Watson and Crick elucidated the structure of the DNA molecule, and since geneticists began unraveling the meaning of the genetic code, the center of gravity of evolution theory has gradually shifted away from the earth sciences – geology and pale-ontology – toward molecular biology.
[174>] This shift in emphasis has occurred not only because of the attraction of the new biology as holding the answers to many puzzling questions, but also because the traditional sciences have proved ultimately sterile as a source of decisive evidence. The gaps in the fossil record, the incomplete-ness of the geological strata, and the ambiguity of the evidence from comparative anatomy, ultimately caused Darwinists to give up and look somewhere else for decisive evidence. Thanks to molecular biology and computer science they now have somewhere else to try.
Darwinists seem to have drawn immense comfort from their recent discoveries at the cellular level and beyond, behaving and speaking as though the new discoveries of biology represent a triumphant vindication of their long-held beliefs over the irrational ideas of vitalists. Yet the gulf between what Darwinists claim for molecular biological discoveries and what those discoveries actually show is only too apparent to any objective evaluation.
Consider these remarks by Francis Crick, justly famous as one of the biologists who cracked the genetic code, and equally well known as an ardent supporter of Darwinist evolution. In his 1966 book Molecules and Men, in which he set out to criticize vitalism, Crick asked which of the various molecular biological processes are likely to be the seat of the “vital principle”.[3] “It can hardly be the action of the enzymes,” he says, “because we can easily make this happen in a test tube. Moreover most enzymes act on rather simple organic molecules which we can easily synthesize.”
There is one slight difficulty but Crick easily deals with it; “It is true that at the moment nobody has synthesized an actual enzyme chemically, but we can see no difficulty in doing this in principle, and in fact I would predict quite confidently that it will be done within the next five or ten years.”
A little later, Crick says of mitochondria (important objects in the cell that also contain DNA):
It may be some time before we could easily synthesise such an object, but eventually we feel that there should be no gross difficulty in putting a mitochondrion together from its component parts.
This reservation aside, it looks as if any system of [175>] enzymes could be made to act without invoking any special principles, or without involving material that we could not synthesize in the laboratory. [4]
There is no question that Crick and Watson’s decoding of the DNA molecule is a brilliant achievement and one of the high points of twentieth-century science. But this success seems to me to have led many scientists to expect too much as a result.
Crick’s early confidence that an enzyme would be produced synthetically within five or ten years has not been borne out and biologists are further than ever from achieving such a synthesis. Indeed, reading and rereading the words above with the benefit of hindsight I cannot help but interpret them as saying “we are unable to synthesize any significant part of a cell at present, but this reservation aside, we are able to synthesize any part of the cell.”
Certainly great strides have been made. William Shrive, writing in the McGraw Hill Encyclopedia of Science and Technology, says, “The complete amino acid sequence of several enzymes has been determined by chemical methods. By X-ray crystallographic methods it has even been possible to deduce the exact three-dimensional molecular structure of a few enzymes.”[5] But despite these advances no-one has so far synthesized anything remotely as complex as an enzyme or any other protein molecule.
Such a synthesis was impossible when Crick wrote in 1966 and remains impossible today. It is probably because there is a world of difference between having a neat table that shows the genetic code for all twenty amino acids (Alanine = GCA, Praline = CCA and so on) and knowing how to manufacture a protein. These complex molecules do not simply assemble themselves from a mixture of ingredients like a cup of tea. Something else is needed. What the something else is remains conjectural. If it is chemical it has not been discovered; if it is a process it is an unknown process; if it is a “vital principle” it has not yet been recognized. Whatever the something is, it is presently impossible to build a case either for Darwinism or against vitalism out of what we have learned of the cell and the molecules of which it is composed.
It is easy to see why evolutionists should be so excited about cellular discoveries because the mechanisms they have found appear to [176>] be very simple. But however simple they may seem, as of yet no-one has succeeded in synthesizing any significant original structure from raw materials. We know the code for the building blocks; we don’t know the instructions for building a house with them.
Indeed, the discoveries of biochemistry and molecular biology have raised some rather awkward questions for Darwinists, which they have yet to address satisfactorily. For example, the existence of genetically very simple biological entities, such as viruses, seems to support Darwinist ideas about the origin of life. One can imagine all sorts of primitive life forms and organisms coming into existence in the primeval ocean and it seems only natural that one should find entities that are part way between the living and the nonliving – stepping stones to life as it were. It is only to be expected, says Richard Dawkins, that the simplest form of self-replicating object would merely be that part of the DNA program which says only “copy me”, which is essentially what a virus is.
The problem here is that viruses lack the ability to replicate unless they inhabit a host cell – a fully functioning cell with its own genetic replication mechanisms. So the first virus must have come after the first cell, not before in a satisfyingly Darwinian processes.
But despite minor unresolved problems of this kind Darwinists still have one remaining card to play in support of their theory. It is the strongest card in their hand and the most powerful and decisive evidence in favor of Darwinian evolutionary processes.
[….]
pp. 223-227
[223>] Earlier on I referred to computers and their programs as a fruitful source of comparison with genetic processes since both are concerned with the storage and reliable transmission of large quantities of information. Arguing from analogy is a dangerous practice, but there is one phenome-non connected with computer systems that could be of some importance in understanding biological information processing strategies.
The phenomenon has to do with the computer’s ability to refer to a master list or template and to highlight any exceptions to this master list that it encounters during processing. This “exception reporting” is profoundly important in information processing. For instance, this book was prepared using a word-processing program that has a spelling checker. When invoked, the spell checker reads the typescript of the book and compares each word with its built-in dictionary, highlighting as potential mistakes those it does not recognize. Of course, it will encounter words that are spelled correctly but are not found in a normal dictionary – such as “deoxyribonucleic acid”. But the program is clever enough to allow me to add the novel word to the dictionary, so that the next time it is encountered it will be accepted as correct instead of reported as an exception – as long as I spell it correctly.
In other words, the spelling checker isn’t really a spelling checker. It has no conception of correct spelling. It is merely a mechanism [224>] for reporting exceptions. Using these methods, programmers can get computers to behave in an apparently intelligent or purposeful way when they are really only obeying simple mechanical rules. Not unnaturally, this gives Darwinists much encouragement to believe that life processes may at root be just as simple and mechanical.
In cell biology there are natural chemical properties of complex molecules that lend them-selves to automatic checking and excepting of this kind. For example many molecules are stereospecific – they will attach only to certain other specific molecules and only in special positions. There are also much more complex forms of exception reporting, for instance as part of the brain’s (of if you prefer, the mind’s) cognitive processes: as when we see and recognize a single face in the crowd or hear our name mentioned at a noisy cocktail party.
In the case of the spelling checker, the behavior of the system can be made to look more and more intelligent through a process of learning if, every time it highlights a new word, I add that word to its internal dictionary. If I continue for a long enough time, then eventually, in principle, the system will have recorded every word in the English language and will highlight only words that are indeed misspelled. It will have achieved the near-miraculous levels of efficiency and repeatability that we are used to seeing in molecular biological processes. But something strange has also been happening at the same time – or, rather, two strange things.
The first is that as its vocabulary grows, the spelling checker becomes less efficient at drawing to my attention possible mistakes. This unexpected result comes about in the fallowing way. Remember, the computer knows nothing of spelling, it merely reports exceptions to me. To begin with, it has only, say, 50,000 standard words in its dictionary. This size of dictionary really only covers the common everyday words plus a modest number of proper nouns (for capital cities, common surnames and the like) and doesn’t leave much room for unusual words. It would, for instance include a word like ‘great’ but not the less-frequently used word “grate”.
The result is that if I accidentally type “grate” when I really mean “great”, the spell checker will draw it to my attention. If however, I enlarge the dictionary and add the word “grate”, the spell [225>]checker will ignore it in future, even though the chances are that it will occur only as a typing mis take – except in the rare case where I am writing about coal fires or cookery.
One can generalize this case by saying that when the dictionary has an optimum size of vo-cabulary, I get the best of both worlds: it points out misspellings of the most common words and reports anything unusual which in most cases probably will be an error. (Obviously to work at optimum efficiency the size of dictionary should be matched to the vocabulary of the writer). As the dictionary grows in volume it becomes more efficient in one way, highlighting only real spelling errors, but less efficient in another: it becomes more probable that my typing errors will spell a real word – one that will not be reported – but not the word I mean to use. Paradoxically, although the spelling checker is more efficient, the resulting book is full of contextual errors: ‘pubic’ instead of ‘public’, ‘grate’ instead of ‘great’ and so on.
It requires a human intelligence -a real spelling checker, not a mechanical exception reporter to make sure that the intended result is produced.
I said two strange things have been happening while I have been adding words to the spelling checker. The second is the odd occasion when the system has highlighted a real spelling mistake to me- say, “problem” instead of “problem” – and I have mistakenly told the computer to add the word to its dictionary. This, of course, has the very unfortunate result that in future it will cease to highlight a real spelling mistake and will pass it as correct. The error is no longer an exception it is now a dictionary word.
Under what circumstances am I most likely to issue such a wrong instruction? It is most likely to happen with words that I type most frequently and that I habitually mistype. Anyone who uses a keyboard every day knows that there are many such ‘favorite’ misspelled words that get typed over and over. Once again, only a real spelling checker, a human brain, can spot the error and correct it.
The reason that the computer’s spellchecker breaks down under these circumstances is that the simple mechanisms put in place do not work from first principles. They do not work in what electronics engineers call ‘real time’ (they are not in touch with the real world) and do not employ any real intelligent understanding [226>] of the tasks they are being called on to perform. So although the computer continues to work perfectly as it was designed to, it becomes more and more corrupted from the standpoint of its original function.
I believe that this analogy may well have some relevance to Darwinists’ belief that biological processes can at root be as simple as the spelling checker. It is easy to think of any number of simple cell replication mechanisms that rely on exception reporting of this kind. I believe that if biological processes were so simple, they too would become functionally corrupt unless there is some underlying or overall design process to which the simple mechanisms answer globally, and which is capable of taking action to correct mistakes. This is the mechanism that we see in action in the case of the “eyeless fly”, Drosophila; in Driesch’s experiment with the sea urchin and Balinsky’s with the eyes of amphibians; the ‘field’ that governs the metamorphosis of the butterfly or the reconstitution of the cells of sponges and vertebrates.
Darwinists believe that the only overall control process is natural selection, but the natural selection mechanism could not account for the cases referred to above. Natural selection works on populations, not individuals. It is capable only of tending to make creatures with massively fatal genetic defects die in infancy, or to make populations that are geographically dispersed eventually produce sterile hybrid offspring. It is such a poor feedback mechanism in the sense of exercising an overall regulating effect that it has failed even to eliminate major congenital diseases. Natural selection offers only death or glory: there is no genetic engineering nor holistic supervision of the organism’s integrity. Yet we are asked to believe that a mechanism of such crudity can creatively supervise a program of gene mutation that will restore sight to the eyeless fly.
This is plainly wishful thinking. The key question remains: what is the location of the supervisory agency that oversees somatic development? How does it work? What is it’s connection with the cell structure of the body?
FOOTNOTES
Richard Milton, Shattering the Myths of Darwinism (Rochester, VT: Park Street Press, 1997), 167-176; 223-226.
(Editor’s Note. The author did not footnote what page he was quoting from, he only cited the work itself)
[1] Richard Dawkins, The Blind Watchmaker (London, England: Pearson Longman, 1986).
[2]Andrew Scott, Vital Principles: The Molecular Mechanisms of Life (Oxford, England: Blackwell Publishers, 1988).
[3] Francis Crick, Of Molecules and Men (Seattle, WA: Univ of Washington Press, 1966).
[4]Ibid.
[5]William Shrive, Enymes, in the McGraw-Hill Encyclopedia of Science & Technology (New York, NY: McGraw-Hill Book Company, 1982).
This short South Park clip will set the tone for the Richard Dawkins censoring himself in the face of Islamo-Fascism (via KNOW YOUR MEME):
I was listening to the Rubin Report at work yesterday, and had to post this video of atheists leaders bowing to Islam.
Dave Rubin of “The Rubin Report” shares a DM clip of Richard Dawkins’ chilling appearance on “Piers Morgan Uncensored” which revealed how successful the Muslim’s world’s threats have been to any public figure critical of Islam when Dawkins refuses to comment on the case of the “ISIS bride.”
And a FLASHBACK to an old post [just days before coming over here to my .com] over at my BLOGSPOT:
After Comedy Central cut a portion of a South Park episode following a death threat from a radical Muslim group, Seattle cartoonist Molly Norris wanted to counter the fear. She has declared May 20th “Everybody Draw Mohammed Day.”
Norris told KIRO Radio’s Dave Ross that cartoonists are meant to challenge the lines of political correctness. “That’s a cartoonist’s job, to be non-PC.”
Producers of South Park said Thursday that Comedy Central removed a speech about intimidation and fear from their show after a radical Muslim group warned that they could be killed for insulting the Prophet Muhammad.
The group said it wasn’t threatening South Park producers Trey Parker and Matt Stone, but it included a gruesome picture of Theo Van Gogh, a Dutch filmmaker killed by a Muslim extremist in 2004, and said the producers could meet the same fate. The website posted the addresses of Comedy Central’s New York office and the California production studio where South Park is made.
“As a cartoonist I just felt so much passion about what had happened I wanted to kind of counter Comedy Central’s message they sent about feeling afraid,” Norris said.
Norris has asked other artists to submit drawings of any religious figure to be posted as part of Citizens Against Citizens Against Humor (CACAH) on May 20th.
On her website Norris explains this is not meant to disrespect any religion, but rather meant to protect people’s right to express themselves.
The quick commentary on this swath of Scripture is this:
Concerning the non-virgin bride, there is an element of fraud here. A woman who admitted she was not a virgin was immune from prosecution; only one who pretended to be a virgin bride was subject to execution, and even then, only if her husband accused her. Furthermore, if any man seduced her prior to her betrothal, she needed only publicly confess this fact, and she could require him to marry her and never divorce her. If she was raped in the city, her cries for help would vindicate her. If she was raped in the field, she was presumed innocent and would be vindicated by her own words. Under those circumstances, it is quite reasonable that a woman who married under false claim of virginity was presumed to be guilty of adultery, that is, having sexual relations with someone other than her betrothed during her betrothal.
While this is a response to a particular “meme,” I will be bringing in previous discussions, posts, and ideas to build to a response that should be instructive in approaching other verses or challenges often given to the Christian as evidence that the Bible shows an “evil” God, and thus undermines the Christians reliance on the Bible.
If you want to just go to a refutation of the meme and skip the build-up, you can do so by CLICKING HERE. Otherwise, enjoy the tour through other challenges that end up being the opposite of the claims of the skeptics.
If a man encounters a young woman, a virgin who is not engaged, takes hold of her and rapes her, and they are discovered, the man who raped her must give the young woman’s father 50 silver shekels, and she must become his wife because he violated her. He cannot divorce her as long as he lives. (Deuteronomy 22:28-29)
The meme [upper/right] was posted by my son to engender deeper conversation on his Facebook. I began to post a series of responses giving hints to ways to approach ancient documents. One must REMEMBER this as you read… I am not showing the divine nature of the Bible… I am merely pointing out the generally accepted rules of engagement when approaching ancient literature most legal systems in the West and literary critics accept as a guideline[s] to sift through documents [ancient or new]. These rules are not meant to prove the divine nature of anything. They are however meant to engender a level playing field (if-you-will) to help anyone approach weighty subjects, texts, and the like.
By using these “rules of engagement” we will find that the typical atheist/skeptic who refuses to mature in their approach to these issues use shallow thinking by promoting such “challenges,” so-called. The real purpose of such memes are merely to produce an emotional — visceral — reaction, emotive in nature, having nothing to do with good thinking in any way.
This approach, then, not only makes it easy for the believer to show the folly in such positions, BUT SHOULD make the skeptic pause and contemplate how they are making themselves look in a public place. They [the skeptic] should want to make their case full of gravitas, facts, context, and the like so they can garner a level of respect in their own positions. These memes do just the opposite. They make the skeptic look childish.
(As an aside, almost all of the graphics/pics inserted in my posts will be linked to similarly contextual article or posts.)
This is key:
Raising one’s self-consciousness [awareness] about worldviews is an essential part of intellectual maturity…. The right eyeglasses can put the world into clearer focus, and the correct worldview can function in much the same way. When someone looks at the world from the perspective of the wrong worldview, the world won’t make much sense to him. Or what he thinks makes sense will, in fact, be wrong in important respects. Putting on the right conceptual scheme, that is, viewing the world through the correct worldview, can have important repercussions for the rest of the person’s understanding of events and ideas…. Instead of thinking of Christianity as a collection of theological bits and pieces to be believed or debated, we should approach our faith as a conceptual system, as a total world-and-life view.
Ronald H. Nash, Worldviews in Conflict: Choosing Christianity in a World of Ideas (Grand Rapids, MI: Zondervan, 1992), 9, 17-18, 19.
Okay then, I will cut’n’paste much of the posts/discussion from my son’s Facebook below (with some editing/addition).
RULES OF ENGAGEMENT
This is one reason why people who say they are skeptics really are not all that skeptical… because they do not do the yeoman’s work to know how to accept or reject their own beliefs well nor those beliefs of whom they are challenging. It does a great disservice to themselves AS WELL as others… and really shows a disregard for a world religion that I have not seen shown to the other great religions of the world. Some even will defend these other Religions without knowing the religions own stated positions.
This is the first of a few points I will make.
This is an issue that has many depths to it. And when atheists or skeptics reject the Bible for such verses, they do a disservice to good thinking. And mind you, one of the most important aspects of this debate is how do we approach ancient texts in a fair way. FIRST and FOREMOST, the idea that the writers of the Bible were robotic in their transmission, called in occultism, “automatic writing,” is not what we see here – where the writer gives over control of himself to write [word-for-word] what is being relayed to him or her. Geisler so aptly words the issue this way:
The [biblical authors] who wrote Scripture were not automatons. They were more than recording secretaries. They wrote with full intent and consciousness in the normal exercise of their own literary styles and vocabularies. The personalities of the [biblical authors] were not violated by a supernatural intrusion. The Bible which they wrote is the Word of God, but it is also the words of men. God used their personalities to convey His propositions. The [biblical authors] were the immediate cause of what was written, but God was the ultimate cause.
(See references for this and Aristotle quote to follow, here)
So the idea that the Bible is a word-for-word dictum is NOT the case. The idea that the Bible is not something akin to “automatic writing” has no bearing on if this is the Divine Word of God however. Rather, the Christians concern should be to show the viable nature of the Bible in its internal context. There are techniques to help the truth seeker to do just that. In fact, our courts today incorporate some help in how they approach documents submitted as evidence, and literary-textual critics employ these Grecian helps that Aristotle and others formulated well.
The internal test utilizes one Aristotle’s dictums from his Poetics. He said,
They [the critics] start with some improbable presumption; and having so decreed it themselves, proceed to draw inferences, and censure the poet as though he had actually said whatever they happen to believe, if his statement conflicts with their notion of things…. Whenever a word seems to imply some contradiction, it is necessary to reflect how many ways there may be of understanding it in the passage in question…. So it is probably the mistake of the critics that has given rise to the Problem…. See whether he [the author] means the same thing, in the same relation, and in the same sense, before admitting that he has contradicted something he has said himself or what a man of sound sense assumes as true.
So are there rules that apply to approaching subjects in a fashion that maximizes the best conclusion on the text/topic that is the subject? Yes there is, this list is also from the Greeks and is summed up in these 8-points are summed up well in a short handout to a class I taught at church dealing with how believers should approach Scripture:
1)Rule of Definition: Define the term or words being considered and then adhere to the defined meanings. 2)Rule of Usage: Don’t add meaning to established words and terms. Ask what was the common usage in the culture at that time period. 3)Rule of Context: Avoid using words out of context. Context must define terms and how words are used. 4)Rule of Historical background: Don’t separate interpretation from historical investigation. 5)Rule of Logic: Be certain that words as interpreted agree with the overall premise. 6)Rule of Precedent: Use the known and commonly accepted meanings of words, not obscure meanings for which there is no precedent. 7)Rule of Unity: Even though many documents may be used there must be a general unity among them. 8)Rule of Inference: Base conclusions on what is already known and proven or can be reasonably implied from all known facts.
(These are more fully explained in the outline I wrote for that teaching here)
This is always helpful to the believer to fall back on when skeptics take a single Scripture out of context and uses it as an example of why they reject the Bible. (The same would be said if something was done in similar fashion to such works as Homer’s Iliad, Caesar’s Gallic Wars, a play from Shakespeare, or the like.) These people not only try to show the Bible in a certain light, but take a leap to say Scripture is not divine in how the Christian or Jew think it is. This is a leap that the text does not warrant. Again, the conclusion they make is not warranted by properly approaching the text… in other words they destroy any warrant they feel they have or have shown by sloppy thinking. By creating this “straw-man” they come to a conclusion that is really a non-sequitur, effectively making their position incoherent.
I will talk about two such texts in the next post.
EXAMPLE ONE
Over the years I have been challenged with many verses. While I have responded to this in the past, Dennis Prager’s critiques is hard to beat. This challenge has to do with Deuteronomy 21:18-21. The Scripture and argument go something like this:
“If any man has a stubborn and rebellious son who will not obey his father or his mother, and when they chastise him, he will not even listen to them, 19 then his father and mother shall seize him, and bring him out to the elders of his city at the gateway of his home town. 20 “And they shall say to the elders of his city, ‘This son of ours is stubborn and rebellious, he will not obey us, he is a glutton and a drunkard.’ 21 “Then all the men of his city shall stone him to death; so you shall remove the evil from your midst, and all Israel shall hear of it and fear,” (Deut. 21:18-21).
BEFORE getting to Prager’s rebuttal… let us deal with some qualifications one need to know and apply to a text in order to maximize a skeptical look at said text.
This seemingly harsh punishment for rebellion has been used by the critics of Christianity to infer the moral backwardness of Old Testament ethics. It is easy to throw stones from the comfort of our 21st-century perspective. If you apply our own understanding to this situation… then yes, I would agree with the skeptic. But this is not how thoughtful people approach ancient texts. For instance… there are many gaps from our 21st-Century post Judeo-Christian, Western culture that one should account for.
Some are:
THE LANGUAGE GAP
✦ …Consider how confused a foreigner must be when he reads in a daily newspaper: “The prospectors made a strike yesterday up in the mountains.” “The union went on strike this morning.” “The batter made his third strike and was called out by the umpire.” “Strike up with the Star Spangled Banner.” “The fisherman got a good strike in the middle of the lake.” Presumably each of these completely different uses of the same word go back to the parent and have the same etymology. But complete confusion may result from misunderstanding how the speaker meant the word to be used…. We must engage in careful exegesis in order to find out what he meant in light of contemporary conditions and usage.
We speak English, but the Bible was written in Hebrew and Greek (and a few parts in Aramaic, which is similar to Hebrew). Therefore, we have a language gap; if we don’t bridge it, we won’t fully be able to understand the Bible.
THE CULTURE GAP
If we don’t understand the various cultures of the time in which the Bible was written, we’ll never comprehend its meaning. For example, if we did not know anything about the Jewish culture at the time of Christ, the Gospel of Matthew would be very difficult to grasp. Concepts such as the Sabbath, Jewish rituals, the temple ceremonies, and other customs of the Jews must be under¬stood within cultural context in order to gain the true meaning of the author’s ideas.
THE GEOGRAPHY GAP
A failure to be familiar with geography will hinder learning. For instance, in I Thessalonians 1:8 we read, “For from you sounded out the word of the Lord not only in Macedonia and Achaia, but also in every place your faith [toward] God is spread abroad.” What is so remarkable about this text is that the message traveled so quickly. In order to understand how, it is necessary to know the geography.
Paul had just been there, and when he wrote the letter, very little time had passed. Paul had been with them for a couple of weeks, but their testimony had already spread far. How could that happen so fast? If you study the geography of the area you’ll find that the Ignatian Highway runs right through the middle of Thessalonica. It was the main concourse between the East and the West, and whatever happened there was passed all the way down the line.
THE HISTORY GAP
Knowing the history behind a passage will enhance our comprehension of what was written. In the Gospel of John, the whole key to understanding the interplay between Pilate and Jesus is based on the knowledge of history.
When Pilate came into the land with his emperor worship, it literally infuriated the Jews and their priests. So he was off to a bad start from the very beginning. Then he tried to pull something on the Jews, and when they caught him, they reported him to Rome, and he almost lost his job. Pilate was afraid of the Jews, and that’s why he let Christ be crucified. Why was he afraid? Because he already had a rotten track record, and his job was on the line.
Consider something known as the psychology of testimony. This refers to the way witnesses of the same event recall it with a certain level of discrepancy, based on how they individually observe, process, store, and retrieve the memories of an event.
One person may recall an event in strict chronological order; another may testify according to the principle of the association of ideas. One person may remember events minutely and consecutively, while someone else omits, condenses, or expands. These factors must be considered in comparing eyewitness accounts, and this is why history expects a certain amount of variability in human testimony. For example, let’s say that twelve eyewitnesses observed the same event–a car accident. If those witnesses were called to testify in a court of law, what would the judge think if all twelve witnesses gave the same exact testimony of the event, with every detail being identical? Any good judge would immediately conclude they were in collusion and reject their accounts. The variations of the observations of the eyewitness testimonies actually add to the integrity of their recall.
These are just a few of the many examples one needs to seriously consider when approaching ANY ancient text – especially ancient religious texts.
GENRE (IN THE OLD TESTAMENT)
Law is “God’s law,” they are the expressions of His sovereign will and character. The writings of Moses contain a lot of Law. God provided the Jews with many laws (619 or so). These laws defined the proper relationship with God to each others and the world (the alien)….
History. Almost every OT book contains history. Some books of the Bible are grouped together and commonly referred to as the “History” (Joshua, Kings & Chronicles). These books tell us the history of the Jewish people from the time of the Judges through the Persian Empire…. In the NT, Acts contains some of the history of the early church, and the Gospels also have History as Jesus’ life is told as History….
Wisdom Literature is focus on questions about the meaning of life (Job, Ecclesiastes), practical living, and common sense (Proverbs and some Psalms)….
Poetryis found mostly in the Old Testament and is similar to modern poetry. Since it is a different language, “Hebrew,” the Bible’s poetry can be very different, because it does not translate into English very well….
Prophecy is the type of literature that is often associated with predicting the future; however, it is also God’s words of “get with it” or else. Thus Prophecy also exposes sin and calls for repentance and obedience. It shows how God’s law can be applied to specific problems and situations, such as the repeated warnings to the Jews before their captivity….
Apocalyptic Writing is a more specific form of prophecy. Apocalyptic writing is a type of literature that warns us of future events which, full meaning, is hidden to us for the time being….
Approaching portions of Scripture (or ANY ancient text) knowing even the genre is helpful to dissect it well.
DENNIS PRAGER exemplifies how to approach Deuteronomy 21:18-21 by explaining much of what we have talked about already plus more:
Moving on…
EXAMPLE
In an ongoing discussion at an atheist’s website, I was challenged with how evil God is to kill children with a Bear (2 Kings 2:23-25). I mean children? Here we have proof that God killed innocent children. Or so a light reading would express as much.
This is a post I can truly pat-myself-on-the-back for… because I offered a twist on this that other apologists have not. Let me explain after this verse is read:
He went up from there to Bethel, and while he was going up on the way, some small boys came out of the city and jeered at him, saying, “Go up, you baldhead! Go up, you baldhead!” And he turned around, and when he saw them, he cursed them in the name of the LORD. And two she-bears came out of the woods and tore forty-two of the boys. From there he went on to Mount Carmel, and from there he returned to Samaria. (2 Kings 2:23-25)
It looks like we are seeing God killing kids for essentially – and just as cutely – as a young child gets frustrated and calls a friend “poopy head.”
However, if you come at this ancient text taking the Grecian examples of the credibility afforded a text, and step out of our 21st-Century post Judeo-Christian “Western” culture and ask if there are gaps in our knowledge (historical time periods, who was this written to, who wrote it, does understanding geography help us in understanding this tough verse, does understanding the culture of the writer help [how are the two cultures different], are there hint in the Hebrew that will help us as well, etc) Using this we can ask like any CSI detective:
Who;
What;
When;
Where;
Why;
And How It Happened.
…as well as does the text…
Emphasize something;
Does it repeat a theme in the larger text;
Is it related or unrelated;
Is it alike or similar to other portions of the text or cultures in the area;
Is it true to our modern life in some way.
By doing so we can find out that:
✔ The crowd was in their late teens to early twenties (NOT CHILDREN, but military age, and this is known from other parts of the Bible where the Hebrew is used AS WELL AS from other ancient documents and cultures in the area of the Middle-East); ✔ they were antisemitic (this is known from most of the previous passages and books as well – also historical anthropology and other ancient texts); ✔ they were from a violently cultic city (ditto); ✔ the crowd was large (large enough to do the following….
(Here is my “pat-on-the-back” coming up)
✔ this large crowd had already turned violent and riotess.
I can say this because as the pictures of cultural customs from this time-period [key!] show on my in-depth response to this by using drawings of historical figures from Israels history: priests, prophets, spiritual leaders, and even Flavius Josephus.
What did you notice above in the cover to an A&E documentary to the right? Yup, a turban as well as a cloak which covers the heads of the priests and prophets. Take note of the below as well.
The Jewish High Priests Annas (Ananus) and Caiaphas
Samuel anointing Saul
King David
I will post continue with a snippet from the aforementioned post:
I posted multiple images to drive a point home in our mind. The prophet Elisha would have had a couple cultural accoutrements that changes this story from simple name calling to an assault. He wouldn’t have been alone either, in other words, he would have had some people attached to him that would lay down their lives to protect him. And secondly, he would have had a head covering on, especially since he was returning from a “priestly” intervention. So we know from cultural history the following:
He would have had a head dressing on — some sort of turbin; and he would have had an entourage of men to dissuade any attack or mistreatment of a priest of Israel on a journey.
One last point before we bullet point the complete idea behind the Holy and Rightful judgement from the Judge of all mankind. There were 42 persons killed by two bears. Obviously this would require many more than 42 people. Why? What happens when you have a group of ten people and a bear comes crashing out of the bushes in preparation to attack? Every one will immediately scatter! In the debate I pointed out that freezing 42 people and allowing the bears time to go down the line to kill each one would be even more of a miracle than this skeptic would want to allow. So the common sense position would require a large crowd and some sort of terrain to cut off escape. So the crowd would probably have been at least a few hundred.
Also, this holy man of God was coming back from a “mission,” he would have had an entourage with him ~ as already mentioned, as well as having some sort of head-covering on as pictured above ~ as already mentioned.
QUESTION: So, what do these cultural and historical points cause us to rightly assume?
ANSWER: That the crowd could not see that the prophet was bald.
Which means they would have had to of gotten physical — forcefully removing the head covering. Which means also that the men with the prophet Elisha would have also been overpowered. So lets bullet point the points that undermine the skeptics viewpoint.
✔ The crowd was in their late teens to early twenties; ✔ they were antisemitic (this is known from most of the previous passages and books); ✔ they were from a violently cultic city; ✔ the crowd was large; ✔ the crowd had already turned violent.
These points caused God in his foreknowledge to protect the prophet and send in nature to disperse the crowd. Nature is not kind, and the death of these men were done by a just Judge. This explains the actions of a just God better than many of the references I read.
Your welcome.
COMMENT AFTER THIS EXAMPLE
Skeptic’s and liberal leaning persons deride the religious or conservative folks for being shallow and not thinking well, but in fact these rejections of BIG IDEAS and ancient text are done by doing just that — low information positions. which is why I ask people to pause and to think more deeply on their own positions. To learn their position better as well as to know better without making straw-men type arguments the position they are rejecting. In-other-words, Know what you reject, and why you reject it.
AGAIN, bringing this to current examples in our political lives, and repeating myself in a way:
Very rarely do you find someone who is an honest enough skeptic that after watching the above 3 short videos asks questions like: “Okay, since my suggestion was obviously false, what would be the driving presuppositions/biases behind such a production?” “What are my driving biases/presuppositions that caused me to grab onto such false positions?” You see, few people take the time and do the hard work to compare and contrast ideas and facts. A good example of this is taken from years of discussing various topics with persons of opposing views, I often ask if they have taken the time to “compare and contrast.” Here is my example:
I own and have watched (some of the below are shown in high-school classes):
Bowling for Columbine
Roger and Me
Fahrenheit 9/11
Wal-Mart: The High Cost of Low Price
Sicko
An Inconvenient Truth
Loose Change
Zeitgeist
Religulouse
The God Who Wasn’t There
Super-Size Me
But rarely [really never] do I meet someone of the opposite persuasion from me that have watched any of the following (I own and have watched):
Celsius41.11: The Temperature at Which the Brain Dies
FahrenHYPE 9/11
Michael & Me
Michael Moore Hates America
Bullshit! Fifth Season… Read More (where they tear apart the Wal-Mart documentary)
Indoctrinate U
Mine Your Own Business
Screw Loose Change
3-part response to Zeitgeist
Fat-Head
Privileged Planet
Unlocking the Mystery of Life
AFTERTHOUGHT
Just as an afterthought. A skeptic who rejects God and accepts naturalism cannot say rape is wrong like the theist can say this:
RAPE:
theism: evil, wrong at all times and places in the universe — absolutely;
atheism: taboo, it was used in our species in the past for the survival of the fittest, and is thus a vestige of evolutionary progress… and so may once again become a tool for survival — it is in every corner of nature;
pantheism: illusion, all morals and ethical actions and positions are actually an illusion (Hinduism – maya; Buddhism – sunyata). In order to reach some state of Nirvana one must retract from this world in their thinking on moral matters, such as love and hate, good and bad. Not only that, but often times the person being raped has built up bad karma and thus is the main driver for his or her state of affairs (thus, in one sense it is “right” that rape happens).
An example from an “evangelical” atheist:
★ Richard Dawkins: My value judgement itself could come from my evolutionary past. ★ Justin Brierley: So therefore it’s just as random in a sense as any product of evolution. ★ Richard Dawkins: You could say that, it doesn’t in any case, nothing about it makes it more probable that there is anything supernatural. ★ Justin Brierley: Ultimately, your belief that rape is wrong is as arbitrary as the fact that we’ve evolved five fingers rather than six. ★ Richard Dawkins: You could say that, yeah.
In other words they have to BORROW FROM ethics the worldview that they are trying to disprove.
For more on this, see my post noting many more atheist/evolutionary (philosophical naturalism) positions followed to their logical conclusions here:
Here are some questions from a person trying to figure out what I have been getting at. At first they seem like “snarky” comments, but end up in a good honest question.
S.C. said:
So when you say rape was “okay then and not now”, you mean that it was ok according to the people, or according to God? (Or both?)
I say this is snarky because the questioner either was not aware (or on purpose) formulated the question which would only allow for a response that “damned” the responder.
In a very neat book meant to dumb down big ideas in logic, we read the following example that will surely persuade the reader who dislike “Dubya’s” rhetoric:
A false dilemma is an argument that presents a limited set of two possible categories and assumes that everything in the scope of the discussion must be an element of that set. Thus, by rejecting one category, you are forced to accept the other. For example, “In the war on fanaticism, there are no sidelines; you are either with us or with the fanatics.” In reality, there is a third option, one could very well be neutral; and a fourth option, one may be against both; and even a fifth option, one may empathize with elements of both.
Ali Almossawi, An Illustrated Book of Bad Arguments: Learn the Lost Art of Making Sense (New York, NY: The Experiment, 2013), 16.
To backtrack just a bit, I am sure S.C. missed the previous two point response to the meme specifically in the original post on Facebook. So I will post these here for clarity and then pick back up with the convo
Back Tracking
I linked to a post on Dr. William Lane Craig’s Reasonable Faith site explaining some of the issues. Here is an excerpt of the challenge… followed by an excerpt of the response:
…you believe that the Bible is the revealed word of God, as you seem to regarding the existence of Jesus of Nazareth, then how do you find child rape so abhorrent when there is nothing in the Bible condemning it? Indeed, Deuteronomy 22:28-29 NLT says that if a woman (regardless of age) is raped, the rapist must pay her father 50 silvers and marry the woman, which hardly seems a punishment to the rapist. This, of course, excludes engaged women, for whom the punishment for being raped is death if they don’t cry for help (Deuteronomy 22:23-24 NAB). The only instance in which it is only the rapist who is punished is if the victim is engaged (possible but not likely if they are a child), and they cry for help (again, a child would very likely be intimidated into not calling for help, and therefore, by Biblical law, be killed)….
Dr. Craig responds in full, but here is the point I wish to zero in on:
But do your examples even do that? The immorality of rape is immediately given in the seventh of the Ten Commandments “You shall not commit adultery.” Any sexual intercourse outside the bounds of marriage is proscribed by the Bible. So rape is always regarded as immoral in the Bible. That puts a quite different perspective on things. What your complaint really is is that the penalties for rape in the passages you cite seem unduly lenient. You think that the criminal laws against rape needed to be even stronger than they were in ancient Israel. Well, maybe you’re right. What does that prove? There’s no claim that Israel’s laws were perfect or adequately expressed God’s moral will. Jesus himself regarded the Mosaic law on divorce as inadequate and failing to capture God’s ideal will for marriage ( Matthew 5.31-2 ). Maybe the same was true for rape laws. Israel’s criminal statutes were not timeless truths for all societies but were intended for Israel at a certain specific time in its history. Moreover, these statutes are examples of case law: if such-and-such happens, then do so-and-so. These were idealizations which served as guides and might admit all sorts of exceptions and mitigating circumstances (like a child’s being afraid to cry for help).
In any case, Spencer, how much effort have you really made to understand these laws in the cultural context of the ancient Near East? None at all, I suspect; you probably got these passages from some free-thought publication or website and repeat them here with little attempt to understand them. By contrast, Paul Copan in his Is God a Moral Monster? (Baker: 2010) deals with these passages in their historical context, thereby shedding light on their meaning (pp. 118-119). Copan observes that there are three cases considered here:
1. Consensual sex between a man and a woman who is engaged to another man, which was a violation of marriage ( Deuteronomy 22.23 ). Both parties were to be executed. 2. Rape of a woman who is engaged to another man ( Deuteronomy 22.25 ). Only the rapist is executed; the woman is an innocent victim. 3. Seduction of a young woman who is not engaged to another man Deuteronomy 22.28 ; cf . Exodus 22.16-17 ). The seducer is obliged to marry the young woman and provide for her, if she will have him; otherwise her father may refuse him and demand payment of the usual bridal gift (rather like a dowry) anyway. In short, rape was a capital crime in ancient Israel. As for Leviticus 20.13 , this verse prescribes the death penalty for consensual sexual intercourse between two men; that you interpret this passage to condemn a child who is assaulted by a pedophile only shows how tendentious your exegesis is.
If anything, then, the Bible is far stricter in its laws concerning sexual behavior than we are today. So even though appeal to the Bible is no part of my argument for (2), what the Bible teaches about the immorality of rape is right in line with my claim that objective moral values and duties exist.
Another good — short — response is this “cool as Colt 45” response to the same topic incorporating the language and context used in these verses:
So the main challenge is dealt with quite handily herein. However, continued discussion will always ad to the understanding of such a tough topic.
…Continuing…
Remember I am still responding to S.C.’s challenge that was a false dilemma, but try to steer the convo to what I know he means. Keep in mind, things do not fall into place easily, so repeating the same thing multiple times ~ just differently or with additional information ~ will often times make a subject click with an individual. I am hoping this will be the case here.
I respond:
Again, “rape” is not part of that verse. The Bible was the first book to legally codify for an entire culture the punishment of the rapist.
…Let’s compare this with ANE law. Copan writes,
Middle Assyrian laws punished not a rapist but a rapist’s wife and even allowed her to be gang-raped. In other ancient Near Eastern laws, men could freely whip their wives, pull out their hair, mutilate their ears, or strike them –a dramatic contrast to Israel’s laws, which gave no such permission.
The previously posted link to a video uploaded to my YouTube of parents being able to kill their children for disobedience is another oft misquoted verse to make a point without any depth of real understanding 12-minutes long):
You see, these verses do the exact opposite of what the meme says they do. The meme says they support rape… in their full context they are protecting the woman from rape by making death the punishment for the rapist.
AGAIN, for CLARITY purposes:
In Deuteronomy 22:28-29 is appears as if a rape victim is to marry the rapist, the verse is as follows:
“If a man meets a virgin who is not betrothed, and seizes her and lies with her, and they are found, then the man who lay with her shall give to the father of the young woman fifty shekels of silver, and she shall be his wife, because he has violated her. He may not divorce her all his days.”
This issue is, however, addressed in another verse from Exodus in the laws of social justice:
“If a man seduces a virgin who is not betrothed and lies with her, he shall give the bride-price for her and make her his wife. If her father utterly refuses to give her to him, he shall pay money equal to the bride-price for virgins.” (Exodus 22:16–17)
Copan explains that “In each case, the man is guilty. However, the critics’ argument focuses on verses 28–29: the rape victim is being treated like she is her father’s property. She’s been violated, and the rapist gets off by paying a bridal fee. No concern is shown for the girl at all”.
He goes on to say that “The girl’s father (the legal point person) has the right to refuse any such permanent arrangement as well as the right to demand the payment that would be given for a bride, even though the seducer doesn’t marry his daughter (since she has been sexually compromised, marriage to another man would be difficult if not impossible). The girl has to agree with this arrangement, and she isn’t required to marry the seducer. In this arrangement, she is still treated as a virgin”.
So, rather than undermining women this law instead emphasizes their protection…
[….]
…So, I don’t think that these verses are condoning rape. Instead these laws were in place to protect the vulnerable, such as women, should undesirable circumstances arise. No, the Bible nor God condones rape.
S.C. is now understanding a bit more about the context, culture, language, the intended audience, the author, etc. I say this because even if he does not admit it, when you start to ask good questions it means you are becoming invested and interested in an outcome. The real challenge is to get beyond one’s presuppositions and reach a conclusion that may be as minimal as this, “wow, maybe I was wrong in coming at this topic in the past… what can I do to better treat the subject as well as respecting others beliefs.”
Respecting others can often times be respecting friends or family.
So here is the question from S.C.
There seems to be a lot of assumptions made there. Where in the text does it say anything that gives us the idea that “The girl has to agree with this arrangement, and she isn’t required to marry the seducer. In this arrangement, she is still treated as a virgin”?
Some of the answer is already dealt with in detail above. We are incorporating many of the points from the “8-Rules,” Aristotles dictum, Israels cultural mores in a lawless time period as well as the surrounding nations cultural mores. In fact we have used in this post many of the points discussed.
CONTEXT
One we will focus on here is Context:
3) Rule of Context: Avoid using words out of context. Context must define terms and how words are used.
Many a passage of Scripture will not be understood at all without the help afforded by the context; for many a sentence derives all its point and force from the connection in which it stands. (Biblical Hermeneutics, Terry. M. S.. p. 117. 1896.)
[Bible words] must be understood according to the requirements of the context. (Thayer’s Greek?English Lexicon of the New Testament, p. 97.)
Every word you read must be understood in the light of the words that come before and after it. (How to Make Sense, Flesch, Rudolph, p. 51, Harper & Brothers. 1959.)
[Bible words] when used out of context… can prove almost anything. [Some interpreters] twist them… from a natural to a non?natural sense. (Irenaeus, second?century church father, quoted in Inspiration and Interpretation, p. 50, Eerdmans Pub. Co., 1957.)
The meaning must be gathered from the context. (Encyclopedia Britannica, Interpretation of Documents. V. 8, p. 912. 1959.)
A good rule of thumb in life is to remember that Context is King.
So using the language and context of the text in question, remembering these key points (pic to the right), we begin to have the tools to answer the issue ourselves by investigating the language, context of the book itself, history, and the like. Here, Apologetics Press has done precisely that (also noted in what I called the “smooth as Colt 45” video):
…The truth is, however, the Hebrew word in this case translated “seizes” (tapas [see more below on this]) can mean many things. Here are some examples of the way it is translated in Deuteronomy 22:28 in several different English translations:
“lay hold on her” (ASV)
“taking her” (DRA)
“and takes her” (NLV/NAB)
“and hath caught her” (YLT).
By looking at other passages that use the word, we can see that the word tapas sometimes has nothing to do with force, and therefore nothing to do with rape. As Greg Bahnsen has written:
The Hebrew word tapas (“lay hold of her,” emphasized above) simply means to take hold of something, grasp it in hand, and (by application) to capture or seize something. It is the verb used for “handling” the harp and flute (Gen. 4:21), the sword (Ezek. 21:11; 30:21), the sickle (Jer. 50:16), the shield (Jer. 46:9), the oars (Ezek. 27:29), and the bow (Amos 2:15). It is likewise used for “taking” God’s name (Prov. 30:9) or “dealing” with the law of God (Jer. 2:8). Joseph’s garment was “grasped” (Gen. 39:12; cf. 1 Kings 11:30), even as Moses “took” the two tablets of the law (Deut. 9:17)… [T]he Hebrew verb “to handle, grasp, capture” does not in itself indicate anything about the use of force (italics in orig.).
In truth, we use English words in this way on a regular basis. For instance, a brief look at the English word “take” illustrates the point. You can take someone’s cookie, or take a person’s wife, or take a bride to be your wife. The idea of force is not inherent in the word at all. If you take a person in your arms, what have you done? Or if a young man takes a young woman to be his wife, is there force involved? No. Also, think about the English word “hold.” You can take hold of something in a number of ways. We often say that a woman will holdthe child in her arms, or a bridegroom takes a bride to “have and to hold.” The Hebrew wordtapas is acting in exactly the same way as the English words “hold” and “take” are.
In addition, it is clearly evident from the immediate context of Deuteronomy 22 that rape is not being discussed in verses 28-29. We know that for two primary reasons. First, verses 25-27 give a clear instance in which rape is being discussed. In that case, a man raped a woman, she “cried out” (v. 27), but she was in the country and no one was there to help her. The text says that the man who committed the crime “shall die” (v. 25), but the Israelites were supposed to “do nothing to the young woman” since “there is in the young woman no sin worthy of death” (v. 26). It is of great interest that in this clear case of rape, the text uses a completely different word. The word translated “forces her” in verse 25 is the Hebrew word chazaq and yet in verse 28, the verb has been intentionally changed to tapas (see Shamoun, 2015). Second, the natural reading of verses 28-29 makes it evident that both parties are guilty of at least some of the blame. Notice that at the end of verse 28 the text says, “and they are found out.” When the passage discusses the obvious case of rape, the text specifically only mentions the man in verse 25 when it says “then only the man who lay with her,” and conspicuously leaves out any indication of “they” being involved in the sin. Dr. Bahsen compares Deuteronomy 22:28-29 to Exodus 22:16, which reads, “If a man entices a virgin who is not betrothed, and lies with her, he shall surely pay the bride-price for her to be his wife” (1992). Notice that in this verse in Exodus, there is no force and both parties shoulder some of the guilt.
The practical value of God’s instruction in Deuteronomy 22:28-29 is easy to see. A man has sexual intercourse with a young woman who is not betrothed to anyone. There is no force involved, and it is not rape. But their action has been discovered. Now, who in the land of Israel wanted to marry a young girl who has not kept herself pure? The man cannot walk away from his sin. He has put the young woman in a very difficult life situation, in which there would be few (or no) other men who would want to marry her. Since it was often the case that women had an extremely difficult time financially without the help of a husband, this would be even more devastating to the young woman. God holds both the parties accountable, instructing them to get married and stay together, both suffer the shame, and work through the difficulties that they have brought on themselves. Nothing could be more moral, loving, and wise than these instructions. Once again, the skeptical charge against God’s love is without foundation.
MOST COMPASSIONATE LAW
Just to repeat an important note:
Again, “Nothing could be more moral, loving, and wise than these instructions in that area and culture.” Why? Because it, for the first time in the ancient world, stripped the power of choice away from men and allowed for choice in the woman’s decision. Sexual abuse, including rape, are prohibited in Scripture. In a Blaze article addressing modern myths regarding the Bible and various sexual behaviors, Rabbi Aryeh Spero and Rabbi Moshe Averick (and others) bring clarity to the argument that the Bible requires a woman to marry her rapist:
Averick addressed Deuteronomy — the book that is most targeted by biblical critics.
“The ‘rape’ that is talked about in Dvarim (Deuteronomy), is obviously not criminal rape; it is talking about a case where a relationship between a young man and woman got out of hand,” he said. “Sexual relationships in a Torah society are strictly forbidden before marriage — dating is only for purposes of marriage in the Orthodox community.”
Averick also pointed out that in Jewish law, women cannot be forced to marry against her will. If a man does not fulfill his duties as a husband, the woman is “entitled to initiate divorce proceedings.” The “rapist,” or fornicator, is not allowed to initiate such proceedings but is obligated to fulfill spousal duties.
This requirement that a “rapist” marry the violated woman, Bock noted, was enacted in order to protect the woman whom he defiled with his sexual advances.
“His act has rendered her unacceptable as a wife for others,” he explained. “So this law was designed to indicate responsibility in the sex act for the person in a patriarchal context where women had little power and where the women if left to the event would be on her own.”
Nettelhorst acknowledged that in a modern context, the situation mentioned in Deuteronomy “sounds awful,” and it was not ideal at the time it occurred either, but the idea was to, again, protect the woman and discourage sexual immorality. By marrying her, the “rapist” was accepting the consequences of his actions, paying her father a restitution and taking on the responsibilities of a husband to provide protection and security.
Spero added that a rape victim could “opt out” of marrying her rapist if she so desired, for, “if not, men could forcibly bring to altar any single woman he desired simply by raping her.”
CONCLUSION TO FIRST QUESTION
BTW, the penalty was 10-years wages, AND marriage to provide for and feed, house, and raise children with this wife… IF SHE SO DESIRED! Which often times she did, considering that the “rape” spoken of here isn’t violent but a more consensual fling. And considering the importance placed on virginity in that time period. One author notes:
…it could be viewed as merciful to the woman, who, because of the rape, would be considered unmarriageable. In that culture, a woman without a husband would have a very difficult time providing for herself. Unmarried women often had no choice but to sell themselves into slavery or prostitution just to survive.
[….]
That punishment consisted of two parts: he must pay the woman’s father fifty shekels of silver and he must marry and support the woman for the rest of her life. Fifty shekels of silver was a very substantial fine as at that time a shekel was a measurement of weight and not an actual coin. Some scholars believe it could have represented as much as 10 years of wages for the average person. The fact that a man was in any way punished for rape was revolutionary for that period of time in history. No other ancient legal system punished rape to anywhere near the degree outlined in Deuteronomy 22:22-29. While it is unrealistic to say that because of this command rape never occurred, hopefully the severity of the punishment was a strong deterrent to the exceedingly evil act of rape. …
That should explain WELL the verse [verses] used out of context to engender emotive responses based in just that, feelings.
NOT TO MENTION that no where in Israels ancient writings, rabbinical tradition and writings [etc.], did the position taken in the meme ever get recorded historically. Showing that how the people of the time understood exactly what was meant by this codified law. This is another clue to show the skeptics grasping at straws to build a straw-man position and attack it.
ANOTHER POINT MADE BY S.C.
I understand that the earlier verses in the chapter are referring to consensual sex, but to me passage 28 specifically cannot be about consensual relations when it uses the term “seize” (or “lay hold”, depending on which translation you are using). A Strongs concordance search of this shows that this term was used to show the taking of something, or someone, without consent, in multiple passages throughout the Bible.
I respond as well as a person in an apologetics group I am a part of (thanks to Z.E. Kendall for his insight… I was on the same track with …USE SKILLFULLY)
No, you have it backwards… the earlier verses talk about rape, the later talks about a more consensual relation.
✦ A primitive root; TWOT 2538; GK 9530; 65 occurrences; AV translates as “take” 27 times, “taken” 12 times, “handle” eight times, “hold” eight times, “catch” four times, “surprised” twice, and translated miscellaneously four times. 1 to catch, handle, lay hold, take hold of, seize, wield. 1a (Qal). 1a1 to lay hold of, seize, arrest, catch. 1a2 to grasp (in order to) wield, wield, use skillfully. 1b (Niphal) to be seized, be arrested, be caught, be taken, captured. 1c (Piel) to catch, grasp (with the hands). — James Strong, Enhanced Strong’s Lexicon (Woodside Bible Fellowship, 1995).
“Taphas” is the Hebrew word for “Lay hold on her”, and it can mean “to catch, handle, lay hold, take hold of, seize, wield, USE SKILLFULLY…”. It doesn’t necessitate a wrongful handling, or laying hold of. This verse concerns seduction, not rape. In no way is rape condoned in any part of the Bible, a simple reading of the larger context of Deuteronomy 22:25-29 easily confirms this. Notice that verse 25 gives the Law regarding rape, but uses an entirely different word than that in verses 28-29. The word used in vs 25 is chazaq- “to force”. In the other stories of the Bible that recount rape, none of them use the expression “taphas Shekahb” as in the Deuteronomy 22:28-29 passage.
…As for Deut. 22:28-29, interesting other uses closer to the meaning of Hebrew 8610 in the passage are likely such that the man in the passage “plays her like a harp,” as it were, or “uses her like the bow.” (Genesis 4:21 and Amos 2:15). So yeah, I’d say that enticement or the like is in view there.
The passage is connected with the immediately preceding passage, of course not through the concept of rape but rather, through the concept of outcomes that the parents/father wouldn’t desire.
Good stuff Maynard. And remember the context of the verses leading up to 28-29 dictate this is a woman deceived by a man’s promises, played like a harp. The primitive root meaning of the word means “to manipulate.”
Answering Islam has a good two paragraph section out of their larger post on the topic of rape:
The Hebrew word tapas (“lay hold of her,” emphasized above) simply means to take hold of something, grasp it in hand, and (by application) to capture or seize something. It is the verb used for “handling” the harp and flute (Gen. 4:21), the sword (Ezek. 21:11; 30:21), the sickle (Jer. 50:16), the shield (Jer. 46:9), the oars (Ezek. 27:29), and the bow (Amos 2:15). It is likewise used for “taking” God’s name (Prov. 30:9) or “dealing” with the law of God (Jer. 2:8). Joseph’s garment was “grasped” (Gen. 39:12; cf. I Kings 11:30), even as Moses “took” the two tablets of the law (Deut. 9:17). People are “caught” (I Kings 20:18), even as cities are “captured” (Deut. 20:19; Isa. 36:1). An adulterous wife may not have been “caught” in the act (Num. 5:13). In all of these instances it is clear that, while force may come into the picture from further description, the Hebrew verb “to handle, grasp, capture” does not in itself indicate anything about the use of force.
This verb used in Deuteronomy 22:28 is different from the verb used in verse 25 (chazak, from the root meaning “to be strong, firm”) which can mean “to seize” a bear and kill it (I Sam. 17:35; cf. 2 Sam. 2:16; Zech. 14:13), “to prevail” (2 Sam. 24:4; Dan. 11:7), “to be strong” (Deut. 31:6; 2 Sam. 2:7), etc. Deuteronomy 22:25 thus speaks of a man finding a woman and “forcing her.” Just three verses later (Deut. 25:28), the verb is changed to simply “take hold of” her – indicating an action less intense and violent than the action dealt with in verse 25 (viz., rape).
The author of the above article, Sam Shamoun, responds to Muslims bringing up Deuteronomy 22:28:
My son asked Sari (the woman I am talking to in this post) to continue on with the conversation to its conclusion, to which I pointed the following out to my son for clarity:
It’s simple Dominic, when I bump into someone in Starbucks and they ask me about this verse, I open up my Bible and find these notes (my Bible is to the right || right click on image and choose “open link in new tab” to fully enlarge). When Sari is at Starbucks and pulls out her Bible [insert laugh track] when someone asks about this verse, she has these notes (hers is to the left || right click on image and choose “open link in new tab” to fully enlarge):
Romans 8:7 simply states: “For the mind-set of the flesh is hostile to God because it does not submit itself to God’s law, for it is unable to do so.” (see some commentary below). I can only give so many “helps” to apply to a proper hermeneutic:
original language,
Aristotle’s Dictum,
Greek rules of interpretation (which the courts in Western culture use),
other verses (the Bible interpret’s the Bible ~ Aristotle’s Dictum),
cultural and historical keys to the Hebraic culture,
as well as the others surrounding Israel… etc.
J.C. Ryle said in “Fire! Fire!,” this,
“Beware of manufacturing a god of your own: a god who is all mercy but not just, a god who is all love but not holy, a god who has a heaven for everybody but a hell for none, a god who can allow good and bad to be side by side in time, but will make no distinction between good and bad in eternity. Such a god is an idol of your own, as truly an idol as any snake or crocodile in an Egyptian temple. The hands of your own fancy and sentimentality have made him. He is not the God of the Bible, and beside the God of the Bible, there is no God at all. Beware of making selections from your Bible to suit your taste. Dare not to say, ‘I believe this verse, for I like it. I refuse that, for I cannot reconcile it with my views.’ Nay! But O man, who art thou that repliest against God? By what right do you talk in this way? Surely it were better to say over EVERY chapter in the word, ‘Speak Lord, for thy servant heareth.’ Ah! If men would do this, they would never deny the unquenchable fire.”
To use the laws of logic and reason, to rightfully divide the Word (2 Tim 2:15), to apply laws in the universe discovered by the Greeks — like Newton discovered the law of gravity, it had always been there, it was merely codified.
Men do not make laws. They do but discover them. Laws must be justified by something more than the will of the majority. They must rest on the eternal foundation of righteousness. ~ Calvin Coolidge
All this [and more] in application to the faith in the construct of the Christian-theistic worldview is something non-regenerate men and women have deep lasting trouble with. For they cannot even see [again, even see] the Kingdom of Heaven (John 3:3)… because regeneration brings a new sight, a new awakening to the soul (1 John 2:29; John 3:6; James 1:18). In other words, Sari HAS fleshed (pun intended) it out to its logical conclusion (Psalm 146:8; Luke 24:31), that is, blindness, rebellion, in the sight of something so evident (2 Corinthians 3:16; 2 Kings 6:17).
It is like saying “look at that ‘fast’ car,” contrasted with “look at that ‘slow’ car.” The car stays the same… the word preceding it defines it’s context… and in our culture it could denote a Pinto [a junker piece of shite!] or a Marzoratti [an expensive sports car].
You see, sexual assault [rape] stayed the same — because the culture looked on sexual purity as important. But the word preceding it defines it’s context — AS WELL AS the actions taken after the context is spoken. So the assault stays the same… the modifier denotes a willingness of a non-willingness in the action (AS WELL as the punishment following such an action ~ death penalty or a “shotgun wedding”).
A shotgun wedding is a wedding that is arranged to avoid embarrassment due to an unplanned pregnancy, rather than out of the desire of the participants. The phrase is an American colloquialism, though it is also used in other parts of the world, based on a supposed scenario (usually hyperbole) that the father of the pregnant daughter, almost by accepted custom, must resort to using coercion (such as threatening with a shotgun) to ensure that the man who impregnated her follows through with the wedding.
The use of duress or violent coercion to marry is no longer common in the U.S., although many anecdotal stories and folk songs record instances of such coercion in 18th- and 19th-century America. Often a couple will arrange a shotgun wedding without explicit outside encouragement, and some religious teachings consider it a moral imperative to marry in that situation.
One purpose of such a wedding can be to get recourse from the man for the act of impregnation; another reason is to ensure that the child is raised by both parents. In some cases, as in early America and in the Middle East, a major objective was the restoring of social honor to the mother.…
This is why leftists can say 1-out-of-4 women are sexually assaulted on college campuses… who would want to send their daughter to such a place like higher education. It isn’t until we see that they define an “unwanted kiss” and “rape” as sexual assault (and everything in-between).
The same idea is applied to these verses ~ Ergo, CONTEXT IS KING!
This verse reveals how hopelessly incorrigible and utterly destitute the flesh really is. It is a spiritual anarchist. This demolishes any theory that there is a divine spark in man and that somehow he has a secret bent toward God. The truth is that man is the enemy of God. He is not only dead in trespasses and sins but active in rebellion against God. Man will even become religious in order to stay away from the living and true God and the person of Jesus Christ. Man in his natural condition, if taken to heaven, would start a revolution, and he would have a protest meeting going on before the sun went down! Jacob, in his natural condition, engaged in a wrestling match. He did not seek it, but he fought back when God wrestled with him. It wasn’t until he yielded that he won, my friend. Anything that the flesh produces is not acceptable to God. The so–called good work, the civilization, the culture, and man’s vaunted progress are all a stench in the nostrils of God. The religious works of church people done in the lukewarmness of the flesh make Christ sick to His stomach (see Rev. 3:15–16)….
~ J. Vernon McGee, Thru the Bible Commentary: The Epistles (Romans 1-8), electronic ed., vol. 42 (Nashville: Thomas Nelson, 1991), 145.
The mind-set of the flesh is death because it is enmity against God. The sinner is a rebel against God and in active hostility to Him. If any proof were needed, it is seen most clearly in the crucifixion of the Lord Jesus Christ. The mind of the flesh is not subject to the law of God. It wants its own will, not God’s will. It wants to be its own master, not to bow to His rule. Its nature is such that it cannot be subject to God’s law. It is not only the inclination that is missing but the power as well. The flesh is dead toward God.
~ William MacDonald, Believer’s Bible Commentary: Old and New Testaments, ed. Arthur Farstad (Nashville: Thomas Nelson, 1995), 1709.
As a note/addition to the above dialogue concerning “Darwin & Hitler”… here is a Mein Kampf quote:
“The stronger must dominate and not mate with the weaker, which would signify the sacrifice of its own higher nature. Only the born weakling can look upon this principle as cruel, and if he does so it is merely because he is of a feebler nature and narrower mind; for if such a law [natural selection] did not direct the process of evolution then the higher development of organic life would not be conceivable at all…. If Nature does not wish that weaker individuals should mate with the stronger, she wishes even less that a superior race should intermingle with an inferior one; because in such a case all her efforts, throughout hundreds of thousands of years, to establish an evolutionary higher stage of being, may thus be rendered futile.”
Adolf Hitler, Mein Kampf, translator/annotator, James Murphy [New York: Hurst and Blackett, 1942], pp. 161-162.
Dawkins spells out the contradiction: “As an academic scientist, I am a passionate Darwinian, believing that natural selection is, if not the only driving force in evolution, certainly the only known force capable of producing the illusion of purpose which so strikes all who contemplate nature. But at the same time as I support Darwinism as a scientist, I am a passionate anti-Darwinian when it comes to politics and how we should conduct our human affairs.” A Devils Chaplain: Reflections on Hope, Lies, Science, and Love (New York: Houghton Mifflin, 2003), 10-11.
In another place, he admits to the logic of his own determinism (that people cannot be held responsible for their actions), but emotionally he cannot accept this. See the Dawkins interview by Logan Gage, “Who Wrote Richard Dawkins’s New Book?,”Evolution News (website), October 28, 2006:
Manzari: Dr. Dawkins thank you for your comments. The thing I have appreciated most about your comments is your consistency in the things I’ve seen you’ve written. One of the areas that I wanted to ask you about, and the place where I think there is an inconsistency, and I hoped you would clarify, is that in what I’ve read you seem to take a position of a strong determinist who says that what we see around us is the product of physical laws playing themselves out; but on the other hand it would seem that you would do things like taking credit for writing this book and things like that. But it would seem, and this isn’t to be funny, that the consistent position would be that necessarily the authoring of this book, from the initial conditions of the big bang, it was set that this would be the product of what we see today. I would take it that that would be the consistent position but I wanted to know what you thought about that.
Dawkins: The philosophical question of determinism is a very difficult question. It’s not one I discuss in this book, indeed in any other book that I’ve ever talked about. Now an extreme determinist, as the questioner says, might say that everything we do, everything we think, everything that we write has been determined from the beginning of time in which case the very idea of taking credit for anything doesn’t seem to make any sense. Now I don’t actually know what I actually think about that, I haven’t taken up a position about that, it’s not part of my remit to talk about the philosophical issue of determinism. What I do know is that what it feels like to me, and I think to all of us, we don’t feel determined. We feel like blaming people for what they do or giving people the credit for what they do. We feel like admiring people for what they do. None of us ever actually as a matter of fact says, “Oh well he couldn’t help doing it, he was determined by his molecules.” Maybe we should… I sometimes… Um… You probably remember many of you would have seen Fawlty Towers. The episode where Basil[‘s]… car won’t start and he gives it fair warning, counts up to three, and then gets out of the car and picks up a tree branch and thrashes it within an edge of his life. Maybe that’s what we all ought to… Maybe the way we laugh at Basil Fawlty, we ought to laugh in the same way at people who blame humans. I mean when we punish people for doing the most horrible murders, maybe the attitude we should take is “Oh they were just determined by their molecules.” It’s stupid to punish them. What we should do is say “This unit has a faulty motherboard which needs to be replaced.” I can’t bring myself to do that. I actually do respond in an emotional way and I blame people, I give people credit, or I might be more charitable and say this individual who has committed murders or child abuse of whatever it is was really abused in his own childhood. And so again I might take a…
Manzari: But do you personally see that as an inconsistency in your views?
Dawkins: I sort of do. Yes. But it is an inconsistency that we sort of have to live with otherwise life would be intolerable. But it has nothing to do with my views on religion it is an entirely separate issue.
“For this very reason, make every effort to add to your faith goodness; and to goodness, knowledge; and to knowledge, self-control; and to self-control, perseverance; and to perseverance, godliness; and to godliness, mutual affection; and to mutual affection, love. For if you possess these qualities in increasing measure, they will keep you from being ineffective and unproductive in your knowledge of our Lord Jesus Christ.”
Woe to those who call evil good
and good evil,
who substitute darkness for light
and light for darkness
who substitute bitter for sweet
and sweet for bitter.
Dawkins says:
“What’s to prevent us from saying Hitler wasn’t right? I mean, that is a genuinely difficult question.” (See/hear more)
In other words, there is no absolute moral ethic, Dawkins wants to have a consensus of people agreeing what is “right” and “wrong” — he says as much in the audio above.
Which means that rape and murder are only taboo… not really wrong.
Secondly, there can be no concept of “ought”
What about human actions? They are of no more value or significance than the actions of any other material thing. Consider rocks rolling down a hill and coming to rest at the bottom. We don’t say that some particular arrangement of the rocks is right and another is wrong. Rocks don’t have a duty to roll in a particular way and land in a particular place. Their movement is just the product of the laws of physics. We don’t say that rocks “ought” to land in a certain pattern and that if they don’t then something needs to be done about it. We don’t strive for a better arrangement or motion of the rocks. In just the same way, there is no standard by which human actions can be judged. We are just another form of matter in motion, like the rocks rolling down the hill.
We tend to think that somewhere “out there” there are standards of behaviour that men ought to follow. But according to Dawkins there is only the “natural, physical world”. Nothing but particles and forces. These things cannot give rise to standards that men have a duty to follow. In fact they cannot even account for the concept of “ought”. There exist only particles of matter obeying the laws of physics. There is no sense in which anything ought to be like this or ought to be like that. There just is whatever there is, and there just happens whatever happens in accordance with the laws of physics.
Men’s actions are therefore merely the result of the laws of physics that govern the behaviour of the particles that make up the chemicals in the cells and fluids of their bodies and thus control how they behave. It is meaningless to say that the result of those physical reactions ought to be this or ought to be that. It is whatever it is. It is meaningless to say that people ought to act in a certain way. It is meaningless to say (to take a contemporary example) that the United States and its allies ought not to have invaded Iraq. The decision to invade was just the outworking of the laws of physics in the bodies of the people who governed those nations. And there is no sense in which the results of that invasion can be judged as good or bad because there are no standards to judge anything by. There are only particles reacting together; no standards, no morals, nothing but matter in motion.
Dawkins finds it very hard to be consistent to this system of belief. He thinks and acts as if there were somewhere, somehow standards that people ought to follow. For example in The God Delusion, referring particularly to the Christian doctrine of atonement, he says that there are “teachings in the New Testament that no good person should support”.(6) And he claims that religion favours an in-group/out-group approach to morality that makes it “a significant force for evil in the world”.(7)
According to Dawkins, then, there are such things as good and evil. We all know what good and evil mean. We know that if no good person should support the doctrine of atonement then we ought not to support that doctrine. We know that if religion is a force for evil then we are better off without religion and that, indeed, we ought to oppose religion. The concepts of good and evil are innate in us. The problem for Dawkins is that good and evil make no sense in his worldview. “There is nothing beyond the natural, physical world.” There are no standards out there that we ought to follow. There is only matter in motion reacting according to the laws of physics. Man is not of a different character to any other material thing. Men’s actions are not of a different type or level to that of rocks rolling down a hill. Rocks are not subject to laws that require them to do good and not evil; nor are men. Every time you hear Dawkins talking about good and evil as if the words actually meant something, it should strike you loud and clear as if he had announced to the world, “I am contradicting myself”.
Please note that I am not saying that Richard Dawkins doesn’t believe in good and evil. On the contrary, my point is that he does believe in them but that his worldview renders such standards meaningless.
(Hat-tip to Wintery Knight’s FACEBOOK) In a lively yet in-depth discussion, Piers Morgan drills down to the core of human existence with Stephen C. Meyer, the prominent ‘intelligent design’ advocate. In this Piers Morgan Uncensored special, Meyers firmly rejects the idea that a scientific worldview leads to atheism, arguing instead that ‘the universe requires a creator or cause’. When Richard Dawkin’s name is mentioned, Meyer claims that he actually really loves the atheist firebrand and admires his intensity. Lastly, Morgan and Meyers agree that the question of God’s existence is tied to more than just cold hard facts, but also human nature itself.
Okay, let’s get this party started… right? I had seen a blip of Dawkins admitting — and it really is an admission of sorts — that what Christ wrought [as a worldview] is CULTURALLYwhat he [Dawkins] prefers to live under. He says he prefers this over Islam, but note, he didn’t mention he would rather live under some atheistic program.
“If I had to choose between Christianity and Islam, I’d choose Christianity every single time.”
Because when dialectical materialism comes about as a worldview embedded into government, what do we get? (PDF version of the below)
A recent comprehensive compilation of the history of human warfare, Encyclopedia of Wars by Charles Phillips and Alan Axelrod documents 1763 wars, of which 123 have been classified to involve a religious conflict. So, what atheists have considered to be ‘most’ really amounts to less than 7% of all wars. It is interesting to note that 66 of these wars (more than 50%) involved Islam, which did not even exist as a religion for the first 3,000 years of recorded human warfare. Even the Seven Years’ War, widely recognized to be “religious” in motivation, noting that the warring factions were not necessarily split along confessional lines as much as along secular interests.
CHRISTIANITY (Crusades)
9 Total Crusades from 1095-1272 A.D;
The crusades lasted about 177 years;
bout 1-million deaths – this includes: disease, the selling into slavery, and died en-route to the Holy land;
… a minimum of 28 million African were enslaved in the Muslim Middle East. Since, at least, 80 percent of those captured by Muslim slave traders were calculated to have died before reaching the slave market, it is believed that the death toll from 1400 years of Arab and Muslim slave raids into Africa could have been as high as 112 Million. When added to the number of those sold in the slave markets, the total number of African victims of the trans-Saharan and East African slave trade could be significantly higher than 140 million people. – John Allembillah Azumah, author of The Legacy of Arab-Islam in Africa: A Quest for Inter-religious Dialogue
As an aside… about 5.714 [yes, point] people were killed a year by the Spanish Inquisition [if you take the highest number] over its 350-year long stretch if you use the leading historian on the topic.
Another aside: the Crusades were largely an operation to free people, whereas Islamic caliphates [jihad] were to convert and enslave people.
Some Resources Used
Alan Axelrod & Charles Phillips, Encyclopedia of Wars, 3 volumes (New York, NY: Facts on File, 2005);
John Entick, The General History of the Late War (Volume 3); Containing It’s Rise, Progress, and Event, in Europe, Asia, Africa, and America (Reprinted by Hard Press; date of publication was from about 1765-1766);
William T. Cavanaugh, The Myth of Religious Violence (New York, NY: Oxford University Press, 2009);
Gordon Martel, The Encyclopedia of War, 5 Volumes (New Jersey, NJ: Wiley, 2012);
Henry Kamen, The Spanish Inquisition: A Historical Revision (London, England: Yale University Press, 1997);
(8-authors) The Black Book of Communism: Crimes, Terror, Repression (Cambridge, MA: Harvard University Press, 1999);
J. Rummel, Death by Government: Genocide and Mass Murder Since 1900 (New York, NY: Routledge Publishers, 1997);
Jung Chang and Jon Halliday, Mao: The Unknown Story (New York, NY: Anchor Books, 2005);
M. Davis, House of War: Islam’s Jihad Against the World (Washington, D.C.: WND Books, 2015);
Islamic Jihad: A Legacy of Forced Conversion, Imperialism, and Slavery (Bloomington, IN: iUniversity, 2009).
Not only were students able to demonstrate the paucity of evidence for this claim, but we helped them discover that the facts of history show the opposite: religion is the cause of a very small minority of wars. Phillips and Axelrod’s three-volume Encyclopedia of Wars lays out the simple facts. In 5 millennia worth of wars—1,763 total—only 123 (or about 7%) were religious in nature (according to author Vox Day in the book The Irrational Atheist). If you remove the 66 wars waged in the name of Islam, it cuts the number down to a little more than 3%. A second [5-volume] scholarly source, The Encyclopedia of War edited by Gordon Martel, confirms this data, concluding that only 6% of the wars listed in its pages can be labelled religious wars. Thirdly, William Cavanaugh’s book, The Myth of Religious Violence, exposes the “wars of religion” claim. And finally, a recent report (2014) from the Institute for Economics and Peace further debunks this myth.
In other words, the culturally Christian West seems to diminish the propensity to “war.”
WHICH may be part of the issue, as well as culturally where we are headed with “gender,” “climate legislation/regulation,” “free-speech,” and the like that are bringing a consensus of sorts on the idea of the positive attributes of the Judeo-Christian worldview. Which leads me to my next example… a recent ATLANTIC article. Mr. Thompson starts the article thus:
As an agnostic, I have spent most of my life thinking about the decline of faith in America in mostly positive terms. Organized religion seemed, to me, beset by scandal and entangled in noxious politics. So, I thought, what is there really to mourn? Only in the past few years have I come around to a different view. Maybe religion, for all of its faults, works a bit like a retaining wall to hold back the destabilizing pressure of American hyper-individualism, which threatens to swell and spill over in its absence.
Here, ARMSTRONG & GETTY discuss the article, as two non-believers/cultural Christians themselves:
As they were discussing the issue, I was thinking of this well worn quote from G.K. Chesterton: “Don’t ever take a fence down until you know the reason it was put up.” You should read the entire ATLANTIC article.
Bill Maher recently noted the following:
For all the progressives and academics who refer to Israel as an outpost of Western civilization, like it’s a bad thing, please note: Western civilization is what gave the world pretty much every [expletive] liberal precept that liberals are supposed to adore. Individual liberty, scientific inquiry, rule of law, religious freedom, women’s rights, human rights, democracy, trial by jury, freedom of speech. Please, somebody, stop us before we enlighten again.
Western civ is basically the Greco-Roman/Judaica-Christianity stream of influence. The CHRISTIAN POST, after quoting Maher, finishes their story:
Which, in fact, brings up just what Bill Maher left out in his otherwise thoughtful and compelling monologue. As you might expect from the guy behind the faith-despising faux-documentary Religulous, he’s not quite ready to admit the role of religion in cultivating liberty and human rights. Because Voltaire and Rousseau were anti-religious, they are safe to mention. Locke and King are often praised almost in spite of their deep faith, which Maher never mentioned.
And it is this failure for community, freedom, and following the science (gender) that is chasing people away from secularism… into Western Foundations.
Dave Rubin of “The Rubin Report” talks to Frank Turek author of “I Don’t Have Enough Faith to Be an Atheist” about the collapse of the New Atheist movement; Richard Dawkins admitting that religion may be necessary for a flourishing society; the failure of atheism in providing a sense of purpose and meaning; what prominent atheists like Christopher Hitchens and Sam Harris overlooked; how only religions like Christianity and Judaism can protect a society from the worst elements of radical Islam; the spreading of social justice and woke culture in America’s churches; the case for intelligent design as a part of the story of evolution; how morality always ends up being legislated; Jordan Peterson’s utilitarian view of religion; and much more.
CROSS EXAMINED NOTED: Yes, we know that Dave Rubin is an openly gay man. CrossExamined.org does not always agree with and affirm all the held beliefs of our guests. Dave did not agree with everything Frank said when he was on The Rubin Report last month either. However, it is good to have dialogue and ask questions of non-Christian guests to see if they are open to Christ, as you will hear Frank do with Dave. We also welcome guests who can add value to specific topics on which we do agree. Despite our noted disagreements, Dave gets a lot right.
I will end with this article I found to be an interesting and pleasant read… this is how it ends:
Society appears to have come a long way from initially professing relativism, which rejects any and all standards of truth including moral, to eventually embracing wokism – an utterly aggressive force of imposed “moralistic” judgment. Semantically different, these concepts are actually homogeneous. When objective truth is denied, its place does not remain empty; it is swiftly occupied by opinions and beliefs of the “self,” either formed by individuals themselves or, more commonly, enforced through educational, group and/or societal indoctrination. People who do not love truth or are precluded from seeking it will find themselves confused, easily manipulated and ultimately deceived.
“‘You’, your joys and your sorrows, your memories and ambitions, your sense of personal identity and free will, are in fact no more than the behavior of a vast assembly of nerve cells and their associated molecules.”
Francis Crick, The Astonishing Hypothesis: The Scientific Search for the Soul (New York, NY: Schribner, 1995), 3.
In this short montage I start out with Lewis Wolpert on the “Unthinkable” program with Justin Brierley. According to evolution, love is reducible entirely to natural causes. I add a response I love from a cyber friend (Ken Ammi) via his debate in March 2010 with Michael Sizer (see my upload of just this part). And of course I add Provine for good measure.
…love better coheres within the Christian, mind-first, conception of reality—where love has role, meaning and place in a universe created by a God who is love. (THE GOSPEL COALITION)
Another capacity that would be impossible without free will is the capacity to love. The existentialist writer Jean-Paul Sartre captured this idea well:
The man who wants to be loved does not desire the enslavement of the beloved. He is not bent on becoming the object of passion which flows forth mechanically. He does not want to possess an automaton, and if we want to humiliate him, we need try to only persuade him that the beloved’s passion is the result of a psychological determinism. The lover will then feel that both his love and his being are cheapened… If the beloved is transformed into an automaton, the lover finds himself alone.7
The endowment of men and women with free will inevitably implies the possibility that they might use that free will to choose evil, and to reject love, even the love of God. Hence we must consider some necessary implications of human free will for the structure of nature. If the free will and free choice that God gave to human beings were intended to be genuine, that very fact necessitated that nature should possess a certain degree of autonomy.
C.S. Lewis puts it this way:
People often talk as if nothing were easier than for two naked minds to “meet” or to become aware of each other. But I see no possibility of their doing so except in a common medium which forms their “external world” or environment… What we need for human society is exactly what we have – a neutral something, neither you nor I, which we can both manipulate so as to make signs to each other. I can talk to you because we can both set up sound waves in the common air between us.8
Lewis then points out that this and other neutral fields – matter, in other words – must have a certain fixed nature, a certain autonomy as Lewis calls it. Suppose the contrary were the case. Imagine, for example, that the world was structured in such a way that a beam of wood remained hard and strong when used in the construction of a house, but it became as soft as grass when I hit my neighbour with it. Or if the air refused to carry lies and insults. Indeed, says Lewis:
If the principle were carried to its logical conclusion evil thoughts would be impossible, for the cerebral matter which we use in our thinking would refuse its task when we attempted to frame them. All matter in the neighbourhood of a wicked man would be liable to undergo unpredictable alterations.9
The result would be, of course, that real freedom of human will and choice would be negated.
Nature, then, must have a certain autonomy, in order that there can be a society of beings with free will, able to make real moral decisions for good or evil, and to carry them out in practice. The potential of evil thought and act to produce evil effects cannot be annulled without simultaneously removing the necessary condition for free will to function. This is a moral universe.
So far, so good, but what lies behind all of this? How does this universe come to be a moral universe; and if we are to be free within it, what are the basic conditions for achieving that freedom?
7 J-P. Sartre, Being and Nothingness, New York, Pocket Books, 1984, p. 478.
8 C.S. Lewis, The Problem of Pain, London, HarperCollins, 2002, p. 18.
9 Ibib., p. 21.
Naturalism is self-defeating Richard Dawkins vs. Greg Bahnsen
UPDATED WITH WRETCHED… originally posted August 2014
This evangelism encounter is POWERFUL. Watch an intelligent college student PRESS street-preacher Todd Friel on the requirements to enter Heaven, then receive a biblical explanation.
This post is a response to a question posed to me via my email by an atheist.
I see that you do some apologetics. Here are a few sincere questions that I’ve tried to get answered from Christians like Greg Koukl, but I never seem to get a response. I’m not baiting you by sending you these questions. If you have any thoughts on these issues, I’d appreciate getting to read your opinion.
1. The New Testament makes it clear that its only through faith in Jesus and his sacrifice that humans can enter heaven. Anyone who lived before Jesus started his ministry had no way of having faith in Jesus. Maybe the people of ancient Israel could piece together what they needed to believe to achieve salvation, but for the gentiles or even humans who lived in North America before the birth of Jesus, they would have no knowledge of the nation of Israel. And most certainly they would have no knowledge of a coming messiah or a future person named Jesus and his sacrifice. What I can conclude is that God allowed humans to be born that would have absolutely no chance of avoiding eternal torment in the fires of hell. I’ve been told that human morality proves that God must be a moral being. However, we have an enormous contradiction here. The God in this scenario is not worthy of respect or love because he is not moral. Hitler and Stalin would have to be quite envious of the amount of torment this God would have allowed.
I brought up the idea of Native-Americas (N-A) not hearing the Gospel with my dad. It seemed, to me, unfair that they should not be afforded at least some clarity in an opportunity to be judged before their maker. My dad shared his thoughts on the matter, and it started with a reading from Romans:
18 For God’s wrath is revealed from heaven against all godlessness and unrighteousness of people who by their unrighteousness suppress the truth, 19 since what can be known about God is evident among them, because God has shown it to them. 20 For His invisible attributes, that is, His eternal power and divine nature, have been clearly seen since the creation of the world, being understood through what He has made. As a result, people are without excuse. (The Holy Bible: Holman Christian Standard Version. [Nashville: Holman Bible Publishers, 2009], Ro 1:18–20.)
But God’s angry displeasure erupts as acts of human mistrust and wrongdoing and lying accumulate, as people try to put a shroud over truth. But the basic reality of God is plain enough. Open your eyes and there it is! By taking a long and thoughtful look at what God has created, people have always been able to see what their eyes as such can’t see: eternal power, for instance, and the mystery of his divine being. So nobody has a good excuse. (Eugene H. Peterson, The Message: The Bible in Contemporary Language [Colorado Springs, CO: NavPress, 2005], Ro 1:18–20.)
He explained that the tribes that were very “war-like,” like the Comanches, acted in rejection of what they knew to be God’s creation and how they should treat their fellow man and nature via the attributes they could clearly interpret via nature. The Sioux were at other times feared as well.
Peaceful tribes – not perfect mind you, but they had a deep understanding of their Creator and how to care for their own and other Native-American tribes they encountered — would interpret nature’s revelatory aspect of Whom they were to worship, and how. The Hopi tribe is one example.
To be clear, when theologians say that God is ultimately sovereign in his decisions over his creation, I am down with this. God — in classical understanding — IS the “Good” and would have a larger view of the panoply of history (since God would be outside of it and viewing it as a whole… the Eternal Now type stuff). So His judgement would necessarily be a Just one. I am not questioning this. I am saying that there are views within orthodoxy that struggle with the boundaries of those who have lived by law seeing that redemption of nature and themselves was somehow woven into nature and never hearing the Gospel (Hebrews 11:9-11). …continuing….
So using the Romans understanding of “The Book of Nature,” and the basis for “unsaved” people seeing – yes, even God’s attributes – something metaphysical and not just material, and looked forward to this hope. Also, these stories of creation and serving a God were handed down from the beginning of mankind. Some people across the earth held close these ancient stories although changed with time.
Combine this with the story of Abraham’s Bosom (Luke 16:19-31) and what Peter tells us about Jesus preaching to these lost souls (I Peter 3:18-20). I would posit — staying within the lane-lines of orthodoxy — that those in the world [pre and post Calvary] who have not been afforded a good explanation of the Gospel message may be afforded an opportunity to respond. This is not me arguing for universalism, but for justice being metered out in some form that was communicated to the Hebraic peoples that is hinted to in the New Testament.
Some Commentary On 1 Peter 3:18-19
This verse raises the two most difficult questions in the letter. When did Jesus preach to the spirits in prison, and who were they? Some take the verse to refer to the chronological sequel to Jesus’ death, when his spirit passed into the realms of the departed. Then, with Acts 2:31 and Eph. 4:9, this verse establishes the clause in the Creeds about Jesus’ descent to the dead. In that case he must have preached to all the dead in one of three ways: to offer them a second chance of salvation; to proclaim his victory over death and triumph over the power of evil and so confirm the sentence on unbelievers and announce deliverance for believers; to proclaim release from purgatory to those who had repented just before they perished in the flood (a popular interpretation among Roman Catholic writers).
Neither the first nor the last of these can be supported from Scripture, but the second has been held by many commentators as fitting in with the NT evidence above. E.G. Selwyn (The First Epistle of Peter [Macmillan, 1949]), and others see the spirits in prison as the fallen angels of Gn. 6:1–8 referred to in 2 Pet. 2:4–10 and Jude 6 as well as in the apocryphal 1 Enoch. Peter’s aim in this context is to demonstrate that God’s purpose is being worked out even in times of suffering. So it would seem best to understand the preaching as a declaration of Christ’s triumph, in order to assert (22) that all angels, authorities and powers [are] in submission to him. Grudem (TNTC) in an appendix summarizes the views and claims that the spirits were Noah’s contemporaries who rejected the preaching of the Spirit of Christ through Noah (see 2 Pet. 2:5) and are now in the prison of the abode of the dead. The interpretation of made alive by the Spirit (18) as a reference to the resurrection, and the spirits in prison as a reference to the fallen angels is cogently argued by R. T. France in New Testament Interpretation, ed. I. H. Marshall (Paternoster Press, 1979), pp. 264–281. He claims that NT and contemporary usage favour this understanding of the word spirits when used by itself, rather than applying it to men and women who had died before Jesus came to bring the gospel.
No view is free of problems, but the use of a verb implying steady and purposeful progression (went [19] and has gone [22] are both the same Gk. word poreutheis) suggests that Peter is recounting what Jesus accomplished between his death and exaltation.
D. A. Carson et al., eds., New Bible Commentary: 21st Century Edition, 4th ed. (Leicester, England; Downers Grove, IL: Inter-Varsity Press, 1994), 1380–1381.
I marry this understanding to a view via William Lane Craig, a name you may be familiar with is on the opposing side of Christian apologetics. He has a view on Molinism I enjoy a bit. [“Enjoy a bit” – I believe is still in the pale of orthodoxy] Here is what he says, and I will emphasize the important aspect I wish to highlight:
The doctrine of Molinism seeks to reconcile God’s sovereign predestination with man’s free will. Through His divine middle knowledge, God can know all possible outcomes of any world that is feasible for Him to create, including all the circumstances required for an individual to come to a saving knowledge of Him. But what if the saving of one individual means the loss of another? Does Molinism provide answers to such a dilemma? In this article, Dr. Craig answers questions on the how God would act if his choices were bound by damning either person A or person B arbitrarily.
I see the solution to your query in your first question in the above. [And the few videos immediately below.]
And it is the same question[s] I struggled with and struggle with. This does away with the contradiction you see. I do wish to note however, that you are taking a moral position in your premise, Saby. And without God, this cannot be the case. Jesus would HAVE to be intimately involved in all of the above scenarios… intimately. None of the above take away from this fact.
I do not know your worldview you operate from, but I can assume atheistic in its presuppositions. But truth (absolute ethical statements are included in this understanding of truth) is something of a fiction to the atheistic evolutionist. Here are some quotes and audio/videos to make my point:
Let’s consider a basic question: Why does the natural world make any sense to begin with? Albert Einstein once remarked that the most incomprehensible thing about the universe is that it is comprehensible. Why should we be able to grasp the beauty, elegance, and complexity of our universe?
Einstein understood a basic truth about science, namely, that it relies upon certain philosophical assumptions about the natural world. These assumptions include the existence of an external world that is orderly and rational, and the trustworthiness of our minds to grasp that world. Science cannot proceed apart from these assumptions, even though they cannot be independently proven. Oxford professor John C. Lennox asks a penetrating question, “At the heart of all science lies the conviction that the universe is orderly. Without this deep conviction science would not be possible. So we are entitled to ask: Where does the conviction come from?”” Why is the world orderly? And why do our minds comprehend this order?
Toward the end of The God Delusion, Dawkins admits that since we are the product of natural selection, our senses cannot be fully trusted. After all, according to Darwinian evolution, our senses have been formed to aid survival, not necessarily to deliver true belief. Since a human being has been cobbled together through the blind process of natural selection acting on random mutation, says Dawkins, it’s unlikely that our views of the world are completely true. Outspoken philosopher of neuro-science Patricia Churchland agrees:
The principle chore of brains is to get the body parts where they should be in order that the organism may survive. Improvements in sensorimotor control confer an evolutionary advantage: a fancier style of representing [the world] is advantageous so long as it… enhances the organism’s chances for survival. Truth, whatever that is, takes the hindmost.
Dawkins is on the right track to suggest that naturalism should lead people to be skeptical about trusting their senses. Dawkins just doesn’t take his skepticism far enough. In Miracles, C. S. Lewis points out that knowledge depends upon the reliability of our mental faculties. If human reasoning is not trustworthy, then no scientific conclusions can be considered true or false. In fact, we couldn’t have any knowledge about the world, period. Our senses must be reliable to acquire knowledge of the world, and our reasoning faculties must be reliable to process the acquired knowledge. But this raises a particularly thorny dilemma for atheism. If the mind has developed through the blind, irrational, and material process of Darwinian evolution, then why should we trust it at all? Why should we believe that the human brain—the outcome of an accidental process—actually puts us in touch with reality? Science cannot be used as an answer to this question, because science itself relies upon these very assumptions.
Even Charles Darwin was aware of this problem: “The horrid doubt always arises whether the convictions of man’s mind, which has developed from the mind of the lower animals, are of any value or at all trustworthy. Would anyone trust the conviction of a monkey’s mind, if there are any convictions in such a mind?” If Darwinian evolution is true, we should distrust the cognitive faculties that make science possible.
Sean McDowell and Jonathan Morrow, Is God Just a Human Invention? And Seventeen Other Questions Raised by the New Atheists (Grand Rapids, MI: Kregel Publications, 2010), 37-38.
….Darwin thought that, had the circumstances for reproductive fitness been different, then the deliverances of conscience might have been radically different. “If . . . men were reared under precisely the same conditions as hive-bees, there can hardly be a doubt that our unmarried females would, like the worker-bees, think it a sacred duty to kill their brothers, and mothers would strive to kill their fertile daughters, and no one would think of interfering” (Darwin, Descent, 82). As it happens, we weren’t “reared” after the manner of hive bees, and so we have widespread and strong beliefs about the sanctity of human life and its implications for how we should treat our siblings and our offspring.
But this strongly suggests that we would have had whatever beliefs were ultimately fitness producing given the circumstances of survival. Given the background belief of naturalism, there appears to be no plausible Darwinian reason for thinking that the fitness-producing predispositions that set the parameters for moral reflection have anything whatsoever to do with the truth of the resulting moral beliefs. One might be able to make a case for thinking that having true beliefs about, say, the predatory behaviors of tigers would, when combined with the understandable desire not to be eaten, be fitness producing. But the account would be far from straightforward in the case of moral beliefs.” And so the Darwinian explanation undercuts whatever reason the naturalist might have had for thinking that any of our moral beliefs is true. The result is moral skepticism.
If our pretheoretical moral convictions are largely the product of natural selection, as Darwin’s theory implies, then the moral theories we find plausible are an indirect result of that same evolutionary process. How, after all, do we come to settle upon a proposed moral theory and its principles as being true? What methodology is available to us?
Paul Copan and William Lane Craig [Mark D. Linville], eds., Contending With Christianity’s Critics: Answering the New Atheists & Other Objections (Nashville, TN: B&H Publishing, 2009), 70.
What about human actions? They are of no more value or significance than the actions of any other material thing. Consider rocks rolling down a hill and coming to rest at the bottom. We don’t say that some particular arrangement of the rocks is right and another is wrong. Rocks don’t have a duty to roll in a particular way and land in a particular place. Their movement is just the product of the laws of physics. We don’t say that rocks “ought” to land in a certain pattern and that if they don’t then something needs to be done about it. We don’t strive for a better arrangement or motion of the rocks. In just the same way, there is no standard by which human actions can be judged. We are just another form of matter in motion, like the rocks rolling down the hill.
We tend to think that somewhere “out there” there are standards of behaviour that men ought to follow. But according to Dawkins there is only the “natural, physical world”. Nothing but particles and forces. These things cannot give rise to standards that men have a duty to follow. In fact they cannot even account for the concept of “ought”. There exist only particles of matter obeying the laws of physics. There is no sense in which anything ought to be like this or ought to be like that. There just is whatever there is, and there just happens whatever happens in accordance with the laws of physics.
Men’s actions are therefore merely the result of the laws of physics that govern the behaviour of the particles that make up the chemicals in the cells and fluids of their bodies and thus control how they behave. It is meaningless to say that the result of those physical reactions ought to be this or ought to be that. It is whatever it is. It is meaningless to say that people ought to act in a certain way. It is meaningless to say (to take a contemporary example) that the United States and its allies ought not to have invaded Iraq. The decision to invade was just the outworking of the laws of physics in the bodies of the people who governed those nations. And there is no sense in which the results of that invasion can be judged as good or bad because there are no standards to judge anything by. There are only particles reacting together; no standards, no morals, nothing but matter in motion.
Dawkins finds it very hard to be consistent to this system of belief. He thinks and acts as if there were somewhere, somehow standards that people ought to follow. For example in The God Delusion, referring particularly to the Christian doctrine of atonement, he says that there are “teachings in the New Testament that no good person should support”. And he claims that religion favours an in-group/out-group approach to morality that makes it “a significant force for evil in the world”.
According to Dawkins, then, there are such things as good and evil. We all know what good and evil mean. We know that if no good person should support the doctrine of atonement then we ought not to support that doctrine. We know that if religion is a force for evil then we are better off without religion and that, indeed, we ought to oppose religion. The concepts of good and evil are innate in us. The problem for Dawkins is that good and evil make no sense in his worldview. “There is nothing beyond the natural, physical world.” There are no standards out there that we ought to follow. There is only matter in motion reacting according to the laws of physics. Man is not of a different character to any other material thing. Men’s actions are not of a different type or level to that of rocks rolling down a hill. Rocks are not subject to laws that require them to do good and not evil; nor are men. Every time you hear Dawkins talking about good and evil as if the words actually meant something, it should strike you loud and clear as if he had announced to the world, “I am contradicting myself”.
Please note that I am not saying that Richard Dawkins doesn’t believe in good and evil. On the contrary, my point is that he does believe in them but that his worldview renders such standards meaningless.
Even Darwin had some misgivings about the reliability of human beliefs. He wrote, “With me the horrid doubt always arises whether the convictions of man’s mind, which has been developed from the mind of lower animals, are of any value or at all trustworthy. Would any one trust in the convictions of a monkey’s mind, if there are any convictions in such a mind?”
Given unguided evolution, “Darwin’s Doubt” is a reasonable one. Even given unguided or blind evolution, it’s difficult to say how probable it is that creatures—even creatures like us—would ever develop true beliefs. In other words, given the blindness of evolution, and that its ultimate “goal” is merely the survival of the organism (or simply the propagation of its genetic code), a good case can be made that atheists find themselves in a situation very similar to Hume’s.
The Nobel Laureate and physicist Eugene Wigner echoed this sentiment: “Certainly it is hard to believe that our reasoning power was brought, by Darwin’s process of natural selection, to the perfection which it seems to possess.” That is, atheists have a reason to doubt whether evolution would result in cognitive faculties that produce mostly true beliefs. And if so, then they have reason to withhold judgment on the reliability of their cognitive faculties. Like before, as in the case of Humean agnostics, this ignorance would, if atheists are consistent, spread to all of their other beliefs, including atheism and evolution. That is, because there’s no telling whether unguided evolution would fashion our cognitive faculties to produce mostly true beliefs, atheists who believe the standard evolutionary story must reserve judgment about whether any of their beliefs produced by these faculties are true. This includes the belief in the evolutionary story. Believing in unguided evolution comes built in with its very own reason not to believe it.
This will be an unwelcome surprise for atheists. To make things worse, this news comes after the heady intellectual satisfaction that Dawkins claims evolution provided for thoughtful unbelievers. The very story that promised to save atheists from Hume’s agnostic predicament has the same depressing ending.
It’s obviously difficult for us to imagine what the world would be like in such a case where we have the beliefs that we do and yet very few of them are true. This is, in part, because we strongly believe that our beliefs are true (presumably not all of them are, since to err is human—if we knew which of our beliefs were false, they would no longer be our beliefs).
Suppose you’re not convinced that we could survive without reliable belief-forming capabilities, without mostly true beliefs. Then, according to Plantinga, you have all the fixins for a nice argument in favor of God’s existence For perhaps you also think that—given evolution plus atheism—the probability is pretty low that we’d have faculties that produced mostly true beliefs. In other words, your view isn’t “who knows?” On the contrary, you think it’s unlikely that blind evolution has the skill set for manufacturing reliable cognitive mechanisms. And perhaps, like most of us, you think that we actually have reliable cognitive faculties and so actually have mostly true beliefs. If so, then you would be reasonable to conclude that atheism is pretty unlikely. Your argument, then, would go something like this: if atheism is true, then it’s unlikely that most of our beliefs are true; but most of our beliefs are true, therefore atheism is probably false.
Notice something else. The atheist naturally thinks that our belief in God is false. That’s just what atheists do. Nevertheless, most human beings have believed in a god of some sort, or at least in a supernatural realm. But suppose, for argument’s sake, that this widespread belief really is false, and that it merely provides survival benefits for humans, a coping mechanism of sorts. If so, then we would have additional evidence—on the atheist’s own terms—that evolution is more interested in useful beliefs than in true ones. Or, alternatively, if evolution really is concerned with true beliefs, then maybe the widespread belief in God would be a kind of “evolutionary” evidence for his existence.
You’ve got to wonder.
Mitch Stokes, A Shot of Faith: To the Head (Nashville, TN: Thomas Nelson, 2012), 44-45.
I wish to start out with an excerpt from a chapter in my book where I use two scholarly works that use Darwinian naturalism as a guide to their ethic:
Dale Peterson and Richard Wrangham, Demonic Males: Apes and the Origins of Human Violence (New York, NY: Houghton Mifflin Harcourt Publishing, 1997).
Randy Thornhill and Craig T. Palmer, A Natural History of Rape: Biological Bases of Sexual Coercion (Cambridge: MIT Press, 2000).
My incorporation of these works into my book (quote):
“Lest one think this line of thinking is insane, that is: sexual acts are something from our evolutionary past and advantageous; rape is said to not be a pathology but an evolutionary adaptation – a strategy for maximizing reproductive success….. The first concept that one must understand is that these authors do not view nature alone as imposing a moral “oughtness” into the situation of survival of the fittest. They view rape, for instance, in its historical evolutionary context as neither right nor wrong ethically. Rape, is neither moral nor immoral vis-à-vis evolutionary lines of thought, even if ingrained in us from our evolutionary paths of survival. Did you catch that? Even if a rape occurs today, it is neither moral nor immoral, it is merely currently taboo. The biological, amoral, justification of rape is made often times as a survival mechanism bringing up the net “survival status” of a species, usually fraught with examples of homosexual worms, lesbian seagulls, and the like.”
Now, hear from other atheist and evolutionary apologists themselves in regard to the matter:
Richard Dawkins
(h/t: TrueFreeThinker) – A Statement Made by an atheist at the Atheist and Agnostic Society:
Some atheists do believe in ethical absolutes, some don’t. My answer is a bit more complicated — I don’t believe that there are any axiological claims which are absolutely true, except within the context of one person’s opinion.
That is, beauty is in the eye of the beholder, and so are ethics. So, why is Adolf Hitler wrong? Because he murdered millions, and his only justification, even if it were valid, was based on things which he should have known were factually wrong. Why is it wrong to do that? Because I said so. Unless you actually disagree with me — unless you want to say that Adolf Hitler was right — I’m not sure I have more to say.
[side note] You may also be aware that Richard Dawkins stated,
…I asked an obvious question: “As we speak of this shifting zeitgeist, how are we to determine who’s right? If we do not acknowledge some sort of external [standard], what is to prevent us from saying that the Muslim [extremists] aren’t right?”
“Yes, absolutely fascinating.” His response was immediate. “What’s to prevent us from saying Hitler wasn’t right? I mean, that is a genuinely difficult question. But whatever [defines morality], it’s not the Bible. If it was, we’d be stoning people for breaking the Sabbath.”
I was stupefied. He had readily conceded that his own philosophical position did not offer a rational basis for moral judgments. His intellectual honesty was refreshing, if somewhat disturbing on this point….
Stated during an interview with Larry Taunton, “Richard Dawkins: The Atheist Evangelist,” by Faith Magazine, Issue Number 18, December 2007 (copyright; 2007-2008)
Lewis Wolpert
From the video description:
Atheists Trying to Have Their Cake and Eat It Too on Morality. This video shows that when an atheist denies objective morality they also affirm moral good and evil without the thought of any contradiction or inconsistency on their part.
Dan Barker
This is from the video Description for the Dan Barker video below:
The atheist’s animal-level view of “morality” is completely skewed by dint of its lack of objectivity. In fact, the atheist makes up his own personal version of “morals” as he goes along, and this video provides an eye-opening example of this bizarre phenomenon of the atheist’s crippled psyche:
During this debate, the atheist stated that he believed rape was morally acceptable, then he actually stated that he would rape a little girl and then kill himself — you have just got to hear his psychotic words with your own ears to believe it!
He then stammered and stumbled through a series of ridiculously lame excuses for his shameful lack of any type of moral compass.
To the utter amazement of his opponent and all present in the audience, the gruesomely amoral atheist even goes so far as to actually crack a sick little joke on the subject of SERIAL CHILD-RAPE!
:::shudders:::
Meanwhile, the Christian in the video gracefully and heroically realizes the clearly objective moral values that unquestionably come to humanity by God’s grace, and yet are far beyond the lower animal’s and the atheist’s tenuous mental grasp. Be sure to keep watching until the very end so that you can hear the Christian’s final word — it’s a real knuckle-duster!
Atheist dogma™ not only fails to provide a stable platform for objective human morality for its adherent — it precludes him even the possibility. It’s this very intellectual inability to apprehend any objective moral values that leads such believers in atheist dogma™ as Hitler, Stalin, Mao, and Dahmer to commit their horrific atheistic atrocities.
Any believer in atheist dogma™, given sufficient power, would take the exact same course of action that Hitler did, without a moment’s hesitation.
Note as well that evolutionary naturalism has very dogmatic implication, IF — that is — the honest atheist/evolutionist follow the matter to their logical conclusions, via the ineffable Dr. Provine:
William Provine
Atheist and staunch evolutionist Dr. William Provine (who is often quoted by Richard Dawkins) admits what life has in stored if Darwinism is true. The quote comes from his debate here with Dr. Phillip E. Johnson at Stanford University, April 30, 1994.
Sam Harris denies completely free will: “In fact, the concept of free will is a non-starter, both philosophically and scientifically.” This is important — as Stephen Hawking points out in his lecture entitled Determinism: Is Man a Slave or the Master of His Fate — who admitted that if “we are the random products of chance, and hence, not free, or whether God had designed these laws within which we are free.”[1] In other words, do we have the ability to make choices, or do we simply follow a chemical reaction induced by millions of mutational collisions of free atoms? Michael Polyni mentions that this “reduction of the world to its atomic elements acting blindly in terms of equilibrations of forces,” a belief that has prevailed “since the birth of modern science, has made any sort of teleological view of the cosmos seem unscientific…. [to] the contemporary mind.”[2]
Which is why in Hawkings most recent book he says “This book is rooted in the concept of scientific determinism, which implies that the answer to [the question of miracles] is that there are no miracles, or exceptions to the laws of nature.”[3] And hence the spiral from scientism, to determinism, to reductionism: “…so it seems that we are no more than biological machines and that free will is just an illusion.”[4]
[1]Ravi Zacharias, The Real Face of Atheism (Grand Rapids, MI: Baker Books, 2004), 118, 119.
[2]Michael Polanti and Harry Prosch, Meaning (Chicago, IL: Chicago university Press, 1977), 162.
[3]Stephen Hawking and Leonard Mlodinow, The Grand Design (London, England: Bantam Press, 2010), 34.
[4] Ibid., 32.
Ethics and propositions that include ethical choice is one that rejects naturalistic origins. Some more quotes to make the point:
What merit would attach to moral virtue if the acts that form such habitual tendencies and dispositions were not acts of free choice on the part of the individual who was in the process of acquiring moral virtue? Persons of vicious moral character would have their characters formed in a manner no different from the way in which the character of a morally virtuous person was formed—by acts entirely determined, and that could not have been otherwise by freedom of choice.
Mortimer J. Adler, Ten Philosophical Mistakes (New York, NY: Touchstone, 1985), 154.
If what he says is true, he says it merely as the result of his heredity and environment, and nothing else. He does not hold his determinist views because they are true, but because he has such-and-such stimuli; that is, not because the structure of the structure of the universe is such-and-such but only because the configuration of only part of the universe, together with the structure of the determinist’s brain, is such as to produce that result…. They [determinists – I would posit any philosophical naturalist] want to be considered as rational agents arguing with other rational agents; they want their beliefs to be construed as beliefs, and subjected to rational assessment; and they want to secure the rational assent of those they argue with, not a brainwashed repetition of acquiescent pattern. Consistent determinists should regard it as all one whether they induce conformity to their doctrines by auditory stimuli or a suitable injection of hallucinogens: but in practice they show a welcome reluctance to get out their syringes, which does equal credit to their humanity and discredit to their views. Determinism, therefore, cannot be true, because if it was, we should not take the determinists’ arguments as being really arguments, but as being only conditioned reflexes. Their statements should not be regarded as really claiming to be true, but only as seeking to cause us to respond in some way desired by them.
J. R. Lucas, The Freedom of the Will (New York: NY: Oxford University Press, 1970), 114, 115.
He thus acknowledged the need for any theory to allow that humans have genuine freedom to recognize the truth. He (again, correctly) saw that if all thought, belief, feeling, and choice are determined (i.e., forced on humans by outside conditions) then so is the determinists’ acceptance of the theory of determinism forced on them by those same conditions. In that case they could never claim to know their theory is true since the theory making that claim would be self-referentially incoherent. In other words, the theory requires that no belief is ever a free judgment made on the basis of experience or reason, but is always a compulsion over which the believer has no control.
Roy A. Clouser, The Myth of Religious Neutrality: An Essay on the Hidden Role of Religious Belief in Theories (Notre Dame, IN: Notre Dame University Press, 2005), 174.
Determinism is self-stultifying. If my mental processes are totally determined, I am totally determined either to accept or to reject determinism. But if the sole reason for my believing or not believing X is that I am causally determined to believe it I have no ground for holding that my judgment is true or false.
J. P. Moreland & William Lane Craig, Philosophical Foundations for a Christian Worldview (Downers Grove, IL: IVP Academic, 2003), 241; Quoting: H.P. Owen, Christian Theism (Edinburgh: T&T Clark, 1984), 118.
Frank Zindler (Editor of American Atheist Magazine and Director of American Atheists Press), denies the existence of free will. In an article he wrote for the American Atheist magazine, he writes this:
Although I risk inciting to disaffection many of the people who have expressed admiration for some of my previous articles, I must now focus my ‘Probing Mind’ upon the question, “Can will be free?” Let me answer the question straightaway with a firm “no,” and then attempt to support my conclusion.
The Center for Naturalism is strongly advocating for widespread rejection of free will:
We should doubt the little god of free will on the very same grounds that atheists doubt the big god of traditional religions: there’s no evidence for it.
I hope this helped and challenged you to know the variability within faith (while remaining orthodox) as well as bringing you face-to-face with your own premises in your worldview. Remember, if you disagree with the above ethics portion, you are not arguing against me but arguing against fellow atheists (if you are an atheist… I would hope you are a soft-agnostic). I also hope you asked your questions in a manner that is in line with you truly seeking a solution to these sticky issues. I will respond to your other challenges (honest questions) at a later date,
Finally, it is objected that the ultimate loss of a single soul means the defeat of omnipotence. And so it does. In creating beings with free will, omnipotence from the outset submits to the possibility of such defeat. What you call defeat, I call miracle: for to make things which are not Itself, and thus to become, in a sense, capable of being resisted by its own handiwork, is the most astonishing and unimaginable of all the feats we attribute to the Deity. I willingly believe that the damned are, in one sense, successful, rebels to the end; that the doors of hell are locked on the inside. I do not mean that the ghosts may not wish to come out of hell, in the vague fashion wherein an envious man “wishes” to be happy: but they certainly do not will even the first preliminary stages of that self-abandonment through which alone the soul can reach any good. They enjoy forever the horrible freedom they have demanded, and are therefore self-enslaved just as the blessed, forever submitting to obedience, become through all eternity more and more free.
C.S. Lewis, The Problem of Pain (New York, NY: Simon & Shuster, 1996), 113-114.
I wanted to share a response to a great, simple question. But first, here is the set up… The Renegade Institute for Liberty at Bakersfield College (whom I will refer to as RENEGADE), a movement of like minded peeps I fully endorse, posted the following on their Facebook:
James Lindsay, a leading critic of the philosophy of the totalitarian left and their politics, penned a manifesto outlying the key moral virtue essential to the preservation of liberty: being based. As used by Lindsay, “based” is a technical term meaning fidelity to truth. He defines it as “the trait of character [is] the willingness to resist lies, be yourself, and tell the truth even when people won’t like you (or will kill you) for it.” Unless most of us become based, totalitarianism is inevitable.
Firstly. The manifesto is well worth it’s weight in salt. I am not saying don’t read it or inculcate some of it’s meaning and ways to approach the issues of our day. Remember the 80/20 rule:
“The person who agrees with you 80 percent of the time is an 80 percent friend and not a 20 percent enemy” – Ronald Wilson Reagan
But as a friend noted today in a Bible study, atheist’s must steal from God – even mentioning the wonderful book by Frank Turek, “Stealing from God.” That is the deeper issue here that I pointed to.
James Lindsay invokes Aleksandr Solzhenitsyn no less than 10-times by name. But James being an ardent atheist/naturalist, never explains to his audience the final conclusion of how Aleksandr Solzhenitsyn believed they got to this miserable place in human history.
Here is my post to the article being linked by RENEGADE, with a longer Solzhenitsyn quote:
RPT NOTE TO POST:
I will read this later today, however, Lindsay could never bring himself to say the following [as a committed atheist, ant-theist]:
“More than half a century ago, while I was still a child, I recall hearing a number of older people offer the following explanation for the great disasters that had befallen Russia: ‘Men have forgotten God; that’s why all this has happened.’ Since then I have spent well-nigh fifty years working on the history of our Revolution; … [and] if I were asked today to formulate as concisely as possible the main cause of the ruinous Revolution that swallowed up some sixty million of our people, I could not put it more accurately than to repeat: ‘Men have forgotten God; that’s why all this has happened.'”
Quoted in Ericson, Edward E. Jr. and Daniel J. Mahoney, The Solzhenitsyn Reader: New and Essential Writings 1947-2005. Wilmington, Del.: ISI Books, 2006, page 577. ____ In other words, the American manifesto acknowledge and remembered God. Any manifesto which does not ends like the Jacobins.
The longer quote is for more context to the video, which I found while doing this post:
….More than half a century ago, while I was still a child, I recall hearing a number of older people offer the following explanation for the great disasters that had befallen Russia: “Men have forgotten God; that’s why all this has happened.”
Since then I have spent well-nigh 50 years working on the history of our Revolution; in the process I have read hundreds of books, collected hundreds of personal testimonies, and have already contributed eight volumes of my own toward the effort of clearing away the rubble left by that upheaval. But if I were asked today to formulate as concisely as possible the main cause of the ruinous Revolution that swallowed up some 60 million of our people, I could not put it more accurately than to repeat: “Men have forgotten God; that’s why all this has happened.”
What is more, the events of the Russian Revolution can only be understood now, at the end of the century, against the background of what has since occurred in the rest of the world. What emerges here is a process of universal significance. And if I were called upon to identify briefly the principal trait of the entire 20th century, here too, I would be unable to find anything more precise and pithy than to repeat once again: “Men have forgotten God.”…
You see, in the end, James Lindsay thinks “God” is part of the problem, not the solution. Which is why I posted that. The totalitarianism Lindsay writes against thrives in godless attire. However, this paragraph I really loved. For one it references “Truth,” something I respond to. And another is this is the reason many comedians are sounding the alarm… the freedom to do even stand up comedy is under attack by the Left.
There are, in the end, only two things that can tear such a regime down, and they are, as it happens, interrelated. They are the two most powerful weapons against tyranny in the human arsenal: telling the truth, including by refusing the lie, and laughter. Both are based, and to win both are necessary. While Solzhenitsyn tells us that the whole of a tyrannical regime can be brought down in the end by a single person repeatedly telling the truth, the fact is that the USSR that tyrannized him actually fell when its subjects—for citizens they were not—began to laugh at it. So, where being based begins in a certain stoicism, it’s the most based when it’s stoicism with a sense of humor. (THE BASE MANIFESTO)
Renegade’s Question:
RENEGADE, for reasons of keeping thought alive, being thorough, a fan of conversation and deeper thinking, asked this simple question:
Sean G, do you think that being based implies believing in God? Or is it consistent with disbelief, as well as belief, in God?
THE REST IS ME, as well as some additions, which I will note.
Great question. Lindsay has a lot of moral pronouncements in the manifesto. A lot. All he has to enforce such things is the power of government. So, in a healthy society, government protects Natural Rights… government does not bestow them. Free speech and thought is a Natural Right, or law, if you will.
“…the separate and equal station to which the Laws of Nature (LN) and of Nature’s God (NG) entitle them…. ‘oh, you know, the thing’.” (Declaration + Joe Biden)
The first (LN) cannot subsist separated from the later (NG) for long.
Having read all three Secular Manifestos, I see similar attributions to “how humans ‘should’ act,” with no reasoning behind it. Utilitarianism? Yes, many aspects therein could be helpful to society as a whole. But if that is it, someone will eventually come along to point out another “utility” as being better.
Take for instance rape. Something you would think everyone would understand as an egregious, absolute, evil.
theism: evil, wrong at all times and places in the universe — absolutely;
atheism: taboo, it was used in our species in the past for the survival of the fittest, and is thus a vestige of evolutionary progress… and so may once again become a tool for survival — it is in every corner of nature;
pantheism: illusion, all morals and ethical actions and positions are actually an illusion (Hinduism – maya; Buddhism – sunyata). In order to reach some state of Nirvana one must retract from this world in their thinking on moral matters, such as love and hate, good and bad. Not only that, but often times the person being raped has built up bad karma and thus is the main driver for his or her state of affairs (thus, in one sense it is “right” that rape happens).
In a bit of an addition here, I will note that some of the four horseman of the New Atheists note that our feeling of being conscience, is illusory. Much like pantheists… which is why many atheists embrace a form of pantheism.
Consciousness an Illusion (Addition)
Below are examples of atheists and theists agreeing that if atheism is true, truth is no longer a category to be trusted (find many more or fuller quotes and videos HERE):
Determinism is self-stultifying. If my mental processes are totally determined, I am totally determined either to accept or to reject determinism. But if the sole reason for my believing or not believing X is that I am causally determined to believe it I have no ground for holding that my judgment is true or false. (H.P. Owen)
If my mental processes are determined wholly by the motions of atoms in my brain, I have no reason to suppose that my beliefs are true…and hence I have no reason for supposing my brain to be composed of atoms. (J.B.S. Haldane)
The principle chore of brains is to get the body parts where they should be in order that the organism may survive. Improvements in sensorimotor control confer an evolutionary advantage: a fancier style of representing [the world] is advantageous so long as it… enhances the organism’s chances for survival. Truth, whatever that is, takes the hindmost. (Patricia Churchland)
He thus acknowledged the need for any theory to allow that humans have genuine freedom to recognize the truth. He (again, correctly) saw that if all thought, belief, feeling, and choice are determined (i.e., forced on humans by outside conditions) then so is the determinists’ acceptance of the theory of determinism forced on them by those same conditions. In that case they could never claim to know their theory is true since the theory making that claim would be self-referentially incoherent. In other words, the theory requires that no belief is ever a free judgment made on the basis of experience or reason, but is always a compulsion over which the believer has no control. (Roy A. Clouser)
If what he says is true, he says it merely as the result of his heredity and environment, and nothing else. He does not hold his determinist views because they are true, but because he has such-and-such stimuli; that is, not because the structure of the structure of the universe is such-and-such but only because the configuration of only part of the universe, together with the structure of the determinist’s brain, is such as to produce that result…. They [determinists – I would posit any philosophical naturalist] want to be considered as rational agents arguing with other rational agents; they want their beliefs to be construed as beliefs, and subjected to rational assessment; and they want to secure the rational assent of those they argue with, not a brainwashed repetition of acquiescent pattern. Consistent determinists should regard it as all one whether they induce conformity to their doctrines by auditory stimuli or a suitable injection of hallucinogens: but in practice they show a welcome reluctance to get out their syringes, which does equal credit to their humanity and discredit to their views. Determinism, therefore, cannot be true, because if it was, we should not take the determinists’ arguments as being really arguments, but as being only conditioned reflexes. Their statements should not be regarded as really claiming to be true, but only as seeking to cause us to respond in some way desired by them. (J. R. Lucas)
…a lecture he attended entitled “Determinism – Is Man a Slave or the Master of His Fate,” given by Stephen Hawking, who is the Lucasian Professor of Mathematics at Cambridge, Isaac Newton’s chair, was this admission by Dr. Hawking’s, was Hawking’s admission that if “we are the random products of chance, and hence, not free, or whether God had designed these laws within which we are free.” In other words, do we have the ability to make choices, or do we simply follow a chemical reaction induced by millions of mutational collisions of free atoms? Michael Polanyi mentions that this “reduction of the world to its atomic elements acting blindly in terms of equilibrations of forces,” a belief that has prevailed “since the birth of modern science, has made any sort of teleological view of the cosmos seem unscientific…. [to] the contemporary mind.”
If we were free persons, with faculties which we might carelessly use or willfully misuse, the fact might be explained; but the pre-established harmony excludes this supposition. And since our faculties lead us into error, when shall we trust them? Which of the many opinions they have produced is really true? By hypothesis, they all ought to be true, but, as they contradict one another, all cannot be true. How, then, distinguish between the true and the false? By taking a vote? That cannot be, for, as determined, we have not the power to take a vote. Shall we reach the truth by reasoning? This we might do, if reasoning were a self-poised, self verifying process; but this it cannot be in a deterministic system. Reasoning implies the power to control one’s thoughts, to resist the processes of association, to suspend judgment until the transparent order of reason has been readied. It implies freedom, therefore. In a mind which is controlled by its states, instead of controlling them, there is no reasoning, but only a succession of one state upon another. There is no deduction from grounds, but only production by causes. No belief has any logical advantage over any other, for logic is no longer possible. (Borden P Bowne)
What merit would attach to moral virtue if the acts that form such habitual tendencies and dispositions were not acts of free choice on the part of the individual who was in the process of acquiring moral virtue? Persons of vicious moral character would have their characters formed in a manner no different from the way in which the character of a morally virtuous person was formed—by acts entirely determined, and that could not have been otherwise by freedom of choice. (Mortimer J. Adler)
Frank Turek notes Daniel Dennett’s dilemma when he says:
Atheist Daniel Dennett, for example, asserts that consciousness is an illusion. (One wonders if Dennett was conscious when he said that!) His claim is not only superstitious, it’s logically indefensible. In order to detect an illusion, you’d have to be able to see what’s real. Just like you need to wake up to know that a dream is only a dream, Daniel Dennett would need to wake up with some kind of superconsciousness to know that the ordinary consciousness the rest of us mortals have is just an illusion. In other words, he’d have to be someone like God in order to know that.
Dennett’s assertion that consciousness is an illusion is not the result of an unbiased evaluation of the evidence. Indeed, there is no such thing as “unbiased evaluation” in a materialist world because the laws of physics determine everything anyone thinks, including everything Dennett thinks. Dennett is just assuming the ideology of materialism is true and applying its implications to consciousness. In doing so, he makes the same mistake we’ve seen so many other atheists make. He is exempting himself from his own theory. Dennett says consciousness is an illusion, but he treats his own consciousness as not an illusion. He certainly doesn’t think the ideas in his book are an illusion. He acts like he’s really telling the truth about reality.
When atheists have to call common sense “an illusion” and make self-defeating assertions to defend atheism, then no one should call the atheistic worldview “reasonable.” Superstitious is much more accurate.
Stealing from God (Colorado Springs, CO: NavPress, 2014), 46-47.
…if evolution were true, then there would be selection only for survival advantage; and there would be no reason to suppose that this would necessarily include rationality. After a talk on the Christian roots of science in Canada, 2010, one atheopathic* philosophy professor argued that natural selection really would select for logic and rationality. I responded by pointing out that under his worldview, theistic religion is another thing that ‘evolved’, and this is something he regards as irrational. So under his own worldview he believes that natural selection can select powerfully for irrationality, after all. English doctor and insightful social commentator Theodore Dalrymple (who is a non-theist himself) shows up the problem in a refutation of New Atheist Daniel Dennett:
Dennett argues that religion is explicable in evolutionary terms—for example, by our inborn human propensity, at one time valuable for our survival on the African savannahs, to attribute animate agency to threatening events.
For Dennett, to prove the biological origin of belief in God is to show its irrationality, to break its spell. But of course it is a necessary part of the argument that all possible human beliefs, including belief in evolution, must be explicable in precisely the same way; or else why single out religion for this treatment? Either we test ideas according to arguments in their favour, independent of their origins, thus making the argument from evolution irrelevant, or all possible beliefs come under the same suspicion of being only evolutionary adaptations—and thus biologically contingent rather than true or false. We find ourselves facing a version of the paradox of the Cretan liar: all beliefs, including this one, are the products of evolution, and all beliefs that are products of evolution cannot be known to be true.
Jonathan D. Sarfati, The Genesis Account: A Theological, Historical, And Scientific Commentary On Genesis 1-11 (Powder Springs, GA: Creation Book Publishers, 2015), 259-259.
Back to the Facebook Exchange
Let us take the secularist’s [atheist] view of rape. Here is a conversation between Richard Dawkins and Justin Brierley. Brierley asks this question, “When you make a value judgement don’t you immediately step yourself outside of this evolutionary process and say that the reason this is good is that it’s good. And you don’t have any way to stand on that statement.” Here is the rest of the conversation:
RICHARD DAWKINS: My value judgement itself could come from my evolutionary past. JUSTIN BRIERLEY:So therefore it’s just as random in a sense as any product of evolution. RICHARD DAWKINS: You could say that, it doesn’t in any case, nothing about it makes it more probable that there is anything supernatural. JUSTIN BRIERLEY: Ultimately, your belief that rape is wrong is as arbitrary as the fact that we’ve evolved five fingers rather than six. RICHARD DAWKINS:You could say that, yeah.
Again, at first Lindsay’s manifesto sounds great, but not lasting in the world he would like to see in reality. He is riding on the fumes of the Judeo-Christian West to expect people to read it and say, “Yeah!”
ADDITION
…I asked an obvious question: “As we speak of this shifting zeitgeist, how are we to determine who’s right? If we do not acknowledge some sort of external [standard], what is to prevent us from saying that the Muslim [extremists] aren’t right?”
“Yes, absolutely fascinating.” His response was immediate. “What’s to prevent us from saying Hitler wasn’t right? I mean, that is a genuinely difficult question. But whatever [defines morality], it’s not the Bible. If it was, we’d be stoning people for breaking the Sabbath.”
I was stupefied. He had readily conceded that his own philosophical position did not offer a rational basis for moral judgments. His intellectual honesty was refreshing, if somewhat disturbing on this point….
Stated during an interview with Larry Taunton, “Richard Dawkins: The Atheist Evangelist,” by Faith Magazine, Issue Number 18, December 2007 (copyright; 2007-2008)
Again, at first Lindsay’s manifesto sounds great, but not lasting in the world he would like to see in reality. He is riding on the fumes of the Judeo-Christian West to expect people to read it and say, “Yeah!”
What thinking in the end — without Nature’s God — could bring us to a lasting consensus?
Here is a favored quote of mine regarding “Beehive Ethics”
….Darwin thought that, had the circumstances for reproductive fitness been different, then the deliverances of conscience might have been radically different. “If . . . men were reared under precisely the same conditions as hive-bees, there can hardly be a doubt that our unmarried females would, like the worker-bees, think it a sacred duty to kill their brothers, and mothers would strive to kill their fertile daughters, and no one would think of interfering” (Darwin, Descent, 82). As it happens, we weren’t “reared” after the manner of hive bees, and so we have widespread and strong beliefs about the sanctity of human life and its implications for how we should treat our siblings and our offspring.
But this strongly suggests that we would have had whatever beliefs were ultimately fitness producing given the circumstances of survival. Given the background belief of naturalism, there appears to be no plausible Darwinian reason for thinking that the fitness-producing predispositions that set the parameters for moral reflection have anything whatsoever to do with the truth of the resulting moral beliefs. One might be able to make a case for thinking that having true beliefs about, say, the predatory behaviors of tigers would, when combined with the understandable desire not to be eaten, be fitness producing. But the account would be far from straightforward in the case of moral beliefs.” And so the Darwinian explanation undercuts whatever reason the naturalist might have had for thinking that any of our moral beliefs is true. The result is moral skepticism.
If our pretheoretical moral convictions are largely the product of natural selection, as Darwin’s theory implies, then the moral theories we find plausible are an indirect result of that same evolutionary process. How, after all, do we come to settle upon a proposed moral theory and its principles as being true? What methodology is available to us?
Paul Copan and William Lane Craig, eds., Contending with Christianity’s Critics: Answering the New Atheists & Other Objections (Nashville, TN: B&H Publishing, 2009), 70.
Using these ideas, one can understand how atheism/atheists cannot justify any “ought” in their ethical construct. And I point out as well that if rape and murder were adventitious for our species and its divisions in the past — for survival means — then logically it can be again for the future. (I use examples like these books: A Natural History of Rape: Biological Bases of Sexual Coercion | Demonic Males: Apes and the Origins of Human Violence.)
I also note that for our species to survive, well, the atheist/evolutionist has no way to determine [evaluate] if the best way for our species to live on is through Western mores and values or if nature prefers the more barbaric aspect of radical Islam.
In another long excerpt, atheistic “ethics” is something temporal, not permanent….
What about human actions? They are of no more value or significance than the actions of any other material thing. Consider rocks rolling down a hill and coming to rest at the bottom. We don’t say that some particular arrangement of the rocks is right and another is wrong. Rocks don’t have a duty to roll in a particular way and land in a particular place. Their movement is just the product of the laws of physics. We don’t say that rocks “ought” to land in a certain pattern and that if they don’t then something needs to be done about it. We don’t strive for a better arrangement or motion of the rocks. In just the same way, there is no standard by which human actions can be judged. We are just another form of matter in motion, like the rocks rolling down the hill.
We tend to think that somewhere “out there” there are standards of behaviour that men ought to follow. But according to Dawkins there is only the “natural, physical world”. Nothing but particles and forces. These things cannot give rise to standards that men have a duty to follow. In fact they cannot even account for the concept of “ought”. There exist only particles of matter obeying the laws of physics. There is no sense in which anything ought to be like this or ought to be like that. There just is whatever there is, and there just happens whatever happens in accordance with the laws of physics.
Men’s actions are therefore merely the result of the laws of physics that govern the behaviour of the particles that make up the chemicals in the cells and fluids of their bodies and thus control how they behave. It is meaningless to say that the result of those physical reactions ought to be this or ought to be that. It is whatever it is. It is meaningless to say that people ought to act in a certain way. It is meaningless to say (to take a contemporary example) that the United States and its allies ought not to have invaded Iraq. The decision to invade was just the outworking of the laws of physics in the bodies of the people who governed those nations. And there is no sense in which the results of that invasion can be judged as good or bad because there are no standards to judge anything by. There are only particles reacting together; no standards, no morals, nothing but matter in motion.
Dawkins finds it very hard to be consistent to this system of belief. He thinks and acts as if there were somewhere, somehow standards that people ought to follow. For example in The God Delusion, referring particularly to the Christian doctrine of atonement, he says that there are “teachings in the New Testament that no good person should support”. And he claims that religion favours an in-group/out-group approach to morality that makes it “a significant force for evil in the world”.
According to Dawkins, then, there are such things as good and evil. We all know what good and evil mean. We know that if no good person should support the doctrine of atonement then we ought not to support that doctrine. We know that if religion is a force for evil then we are better off without religion and that, indeed, we ought to oppose religion. The concepts of good and evil are innate in us. The problem for Dawkins is that good and evil make no sense in his worldview. “There is nothing beyond the natural, physical world.” There are no standards out there that we ought to follow. There is only matter in motion reacting according to the laws of physics. Man is not of a different character to any other material thing. Men’s actions are not of a different type or level to that of rocks rolling down a hill. Rocks are not subject to laws that require them to do good and not evil; nor are men. Every time you hear Dawkins talking about good and evil as if the words actually meant something, it should strike you loud and clear as if he had announced to the world, “I am contradicting myself”.
Please note that I am not saying that Richard Dawkins doesn’t believe in good and evil. On the contrary, my point is that he does believe in them but that his worldview renders such standards meaningless.
In the end, it will take a hyper-intrusively large government to make people see this as the right way to think, if divorced from an “ontological ‘ought’.”
“Twenty times, in the course of my late reading, have I been on the point of breaking out, ‘this would be the best of all possible worlds, if there were no religion in it!!!!’ But in this exclamation, I should have been as fanatical as Bryant or Cleverly. Without religion, this world would be something not fit to be mentioned in public company – I mean hell.”
Charles Francis Adams [ed.], The Works of John Adams, 10 vols. [Boston, 1856], X, p. 254. | Taken from They Never Said It: A Book of Fake Quotes, Misquotes, & Misleading Attributions, by Paul F. Boller, Jr. & John George, p. 3.
“…we have no government, armed with power, capable of contending with human passions, unbridled by morality and religion. Avarice, ambition, revenge and licentiousness would break the strongest cords of our Constitution, as a whale goes through a net. Our Constitution was made only for a moral and religious people. It is wholly inadequate to the government of any other.”
John Adams, first (1789–1797) Vice President of the United States, and the second (1797–1801) President of the United States. Letter to the Officers of the First Brigade of the Third Division of the Militia of Massachusetts, 11 October 1798, in Revolutionary Services and Civil Life of General William Hull (New York, 1848), pp 265-6.
I gave this last parting quote from Mitch Stokes to drive the point home:
Even Darwin had some misgivings about the reliability of human beliefs. He wrote, “With me the horrid doubt always arises whether the convictions of man’s mind, which has been developed from the mind of lower animals, are of any value or at all trustworthy. Would any one trust in the convictions of a monkey’s mind, if there are any convictions in such a mind?”
Given unguided evolution, “Darwin’s Doubt” is a reasonable one. Even given unguided or blind evolution, it’s difficult to say how probable it is that creatures—even creatures like us—would ever develop true beliefs. In other words, given the blindness of evolution, and that its ultimate “goal” is merely the survival of the organism (or simply the propagation of its genetic code), a good case can be made that atheists find themselves in a situation very similar to Hume’s.
The Nobel Laureate and physicist Eugene Wigner echoed this sentiment: “Certainly it is hard to believe that our reasoning power was brought, by Darwin’s process of natural selection, to the perfection which it seems to possess.” That is, atheists have a reason to doubt whether evolution would result in cognitive faculties that produce mostly true beliefs. And if so, then they have reason to withhold judgment on the reliability of their cognitive faculties. Like before, as in the case of Humean agnostics, this ignorance would, if atheists are consistent, spread to all of their other beliefs, including atheism and evolution. That is, because there’s no telling whether unguided evolution would fashion our cognitive faculties to produce mostly true beliefs, atheists who believe the standard evolutionary story must reserve judgment about whether any of their beliefs produced by these faculties are true. This includes the belief in the evolutionary story. Believing in unguided evolution comes built in with its very own reason not to believe it.
This will be an unwelcome surprise for atheists. To make things worse, this news comes after the heady intellectual satisfaction that Dawkins claims evolution provided for thoughtful unbelievers. The very story that promised to save atheists from Hume’s agnostic predicament has the same depressing ending.
It’s obviously difficult for us to imagine what the world would be like in such a case where we have the beliefs that we do and yet very few of them are true. This is, in part, because we strongly believe that our beliefs are true (presumably not all of them are, since to err is human—if we knew which of our beliefs were false, they would no longer be our beliefs).
Suppose you’re not convinced that we could survive without reliable belief-forming capabilities, without mostly true beliefs. Then, according to Plantinga, you have all the fixins for a nice argument in favor of God’s existence For perhaps you also think that—given evolution plus atheism—the probability is pretty low that we’d have faculties that produced mostly true beliefs. In other words, your view isn’t “who knows?” On the contrary, you think it’s unlikely that blind evolution has the skill set for manufacturing reliable cognitive mechanisms. And perhaps, like most of us, you think that we actually have reliable cognitive faculties and so actually have mostly true beliefs. If so, then you would be reasonable to conclude that atheism is pretty unlikely. Your argument, then, would go something like this: if atheism is true, then it’s unlikely that most of our beliefs are true; but most of our beliefs are true, therefore atheism is probably false.
Notice something else. The atheist naturally thinks that our belief in God is false. That’s just what atheists do. Nevertheless, most human beings have believed in a god of some sort, or at least in a supernatural realm. But suppose, for argument’s sake, that this widespread belief really is false, and that it merely provides survival benefits for humans, a coping mechanism of sorts. If so, then we would have additional evidence—on the atheist’s own terms—that evolution is more interested in useful beliefs than in true ones. Or, alternatively, if evolution really is concerned with true beliefs, then maybe the widespread belief in God would be a kind of “evolutionary” evidence for his existence.
You’ve got to wonder.
Mitch Stokes, A Shot of Faith: To the Head (Nashville, TN: Thomas Nelson, 2012), 44-45.
Even if we did not have the New Testament or Christian writings, we would be able to conclude from such non-Christian writings as Josephus, the Talmud, Tacitus, and Pliny the Younger that: 1) Jesus was a Jewish teacher; 2) many people believed that he performed healings and exorcisms; 3) he was rejected by the Jewish leaders; 4) he was crucified under Pontius Pilot in the reign of Tiberius; 5) despite this shameful death, his followers, who believed that he was still alive, spread beyond Palestine so that there were multitudes of them in Rome by A.D. 64; 6) all kinds of people from the cities and countryside – men and women, slave and free – worshipped him as God by the beginning of the second century (100 A.D.)
Michael J. Wilkins, ed., Jesus Under Fire: Modern Scholarship Reinvents the Historical Jesus (Grand Rapids, MI: Zondervan, 1996), 221-222.
The nine founders among the eleven living religions in the world had characters which attracted many devoted followers during their own lifetime, and still larger numbers during the centuries of subsequent history. They were humble in certain respects, yet they were also confident of a great religious mission. Two of the nine, Mahavira and Buddha, were men so strong-minded and self-reliant that, according to the records, they displayed no need of any divine help, though they both taught the inexorable cosmic law of Karma. They are not reported as having possessed any consciousness of a supreme personal deity. Yet they have been strangely deified by their followers. Indeed, they themselves have been worshipped, even with multitudinous idols.
All of the nine founders of religion, with the exception of Jesus Christ, are reported in their respective sacred scriptures as having passed through a preliminary period of uncertainty, or of searching for religious light. Confucius, late in life, confessed his own sense of shortcomings and his desire for further improvement in knowledge and character. All the founders of the non-Christian religions evinced inconsistencies in their personal character; some of them altered their practical policies under change of circumstances.
Jesus Christ alone is reported as having had a consistent God consciousness, a consistent character himself, and a consistent program for his religion. The most remarkable and valuable aspect of the personality of Jesus Christ is the comprehensiveness and universal availability of his character, as well as its own loftiness, consistency, and sinlessness.
Robert Hume, The World’s Living Religions (New York, NY: Charles Scribner’s Sons, 1959), 285-286.
I want to first deal with the “authorship of Mark” challenge. I may deal with the video authors challenge about the Old Testament God — but really this is old news by the “new atheists.” This has been thoroughly dealt with by many, many fine apologists over the years. If I do it will be in a “PART 2” But for now, this will suffice:
Missing The Moral Mark
“If the solar system was brought about by an accidental collision, then the appearance of organic life on this planet was also an accident, and the whole evolution of Man was an accident too. If so, then all our thought processes are mere accidents – the accidental by-product of the movement of atoms. And this holds for the materialists and astronomers as well as for anyone else’s. But if their thoughts — i.e. of Materialism and — are merely accidental by-products, why should we believe them to be true? I see no reason for believing that one accident should be able to give a correct account of all the other accidents. It’s like expecting that the accidental shape taken by the splash when you upset a milk-jug should give you a correct account of how the jug was made and why it was upset.”
C.S. Lewis, God In the Dock (Grand Rapids: Eerdmans Publishing Co., 1970), pp. 52–53.
If a good God made the world why has it gone wrong? And for many years I simply refused to listen to the Christian answers to this question, because I kept on feeling “whatever you say and however clever your arguments are, isn’t it much simpler and easier to say that the world was not made by any intelligent power? Aren’t all your arguments simply a complicated attempt to avoid the obvious?” But then that threw me back into another difficulty.
My argument against God was that the universe seemed so cruel and unjust. But how had I gotten this idea of just and unjust? A man does not call a line crooked unless he has some idea of a straight line. What was I comparing this universe with when I called it unjust? If the whole show was bad and senseless from A to Z, so to speak, why did I, who was supposed to be part of the show, find myself in such violent reaction against it? A man feels wet when he falls into water, because man is not a water animal: a fish would not feel wet. Of course I could have given up my idea of justice by saying it was nothing but a private idea of my own. But if I did that, then my argument against God collapsed too — for the argument depended on saying that the world was really unjust, not simply that it did not happen to please my private fancies. Thus in the very act of trying to prove that God did not exist — in other words, that the whole of reality was senseless — I found I was forced to assume that one part of reality — namely my idea of justice — was full of sense. Consequently, atheism turns out to be too simple. If the whole universe has no meaning, we should never have found out that it has no meaning: just as, if there were no light in the universe and therefore no creatures with eyes, we should never know it was dark. Dark would be without meaning.
C.S. Lewis, Mere Christianity (San Francisco, CA: Harper San Francisco, 1952), 38-39.
In the VIDEO, the author tries to make a connection between the zealots who died following Jim Jones, and what Jesus has called people to in Mark 8:34-35:
34 Calling the crowd along with his disciples, he said to them, “If anyone wants to follow after me, let him deny himself, take up his cross, and follow me.35For whoever wants to save his life will lose it, but whoever loses his life because of me and the gospel will save it. 36 For what does it benefit someone to gain the whole world and yet lose his life?37What can anyone give in exchange for his life?38For whoever is ashamed of me and my words in this adulterous and sinful generation, the Son of Man will also be ashamed of him when he comes in the glory of his Father with the holy angels.”
— Christian Standard Bible (Nashville, TN: Holman Bible Publishers, 2020), Mk 8:34–38.
What are the KEY THEMES via the ESV Study Bible?
But to sum up the people willing to die after Jesus’ ascension, you have a myriad of martyrs being burned alive, fed to lions, and the like. They did not poison themselves or die fighting to convert others. For instance, in 2016 about 90,000 Christians were killed for their faith worldwide. Christians are the most martyred group in the world. Maybe Jesus was foreshadowing this reality’s in His omniscience? (I will post a commentary at the end to show the slightly more complex idea than the simpleton one in the video.)
AUTHORSHIP!
This first – short – video is by J. Warner Wallace, followed by a quick blurb I assume many do not know well… followed still by some more of the same. I wanted to post on this topic because of a video by , the part that got me thinking was the section from the 10:32 mark to the 12:05 time stamps.
LEARN RELIGIONS has this interesting blurb for the uninitiated:
John Mark in the Bible
John Mark was not one of the 12 apostles of Jesus. He is first mentioned by name in the book of Acts in connection with his mother. Peter had been thrown in prison by Herod Antipas, who was persecuting the early church. In answer to the church’s prayers, an angel came to Peter and helped him escape. Peter hurried to the house of Mary, the mother of John Mark, where she was holding a prayer gathering of many of the church members (Acts 12:12).
Both the home and household of John Mark’s mother Mary were important in the early Christian community of Jerusalem. Peter seemed to know that fellow believers would be gathered there for prayer. The family was presumably wealthy enough to have a maidservant (Rhoda) and host large worship meetings.
The earliest manuscripts tell us Mark wrote the Gospel: “according to Mark.” But who was Mark?
Mark, or John Mark, as he was known, lived in Jerusalem, and his mother owned a home where the earliest followers of Jesus gathered. He worked with Paul and Barnabas on their first missionary journey. Later, he joined Peter in Rome. It was in Rome, according to church tradition, where Mark wrote Peter’s version of the Gospel.
Despite this anonymity, there is strong and early tradition identifying the author of the Third Gospel as John Mark, part-time associate of both Paul and Peter. The earliest tradition is reported by the church historian Eusebius (c. AD 263 – 339), who quotes Papias, bishop of Hierapolis, in the latter’s five-volume work known as Interpretation of the Sayings of the Lord (Λογίων κυριακῶν ἑξήγησις). Papias, likely writing around AD 95 – 110,37 quotes John “the Elder” concerning the authorship of the Second Gospel:
The Presbyter used to say this also: “Mark became Peter’s interpreter and wrote down accurately, but not in order, all that he remembered of the things said and done by the Lord. For he had not heard the Lord or been one of his followers, but later, as I said, a follower of Peter. Peter used to teach as the occasion demanded, without giving systematic arrangement to the Lord’s sayings, so that Mark did not err in writing down some things just as he recalled them. For he had one overriding purpose: to omit nothing that he had heard and to make no false statements in his account.”2
Eusebius points out that though Papias did not himself know the apostles, he was in direct contact with those who had heard them, including John the Elder, Aristion, Polycarp, and the daughters of Philip the Evangelist (Eusebius, Hist. eccl. 3.39.1 – 9; cf. Acts 21:8 – 9).3 We thus have a first-century tradition claiming that Mark accurately interpreted (or translated) Peter’s eyewitness accounts, turning Peter’s anecdotal stories into a connected narrative, though not necessarily in chronological order.4
Mark’s authorship in the second century
Second-century sources make similar claims. The Anti-Marcionite Prologue to Mark (c. 160 – 180) identifies Mark as the author and links him to Peter: “Mark . . . who was called ‘stump-fingered’ because for the size of the rest of his body he had fingers that were too short. He was Peter’s interpreter. After the departure [or ‘death’] of Peter himself, the same man wrote his Gospel in the regions of Italy.”5 The odd statement about Mark’s disfigured fingers may point to a reliable tradition, since the church is unlikely to have invented such a disparaging remark.6We find here two additional pieces of information: that Mark wrote after Peter’s death and that he wrote in Italy.
Irenaeus (c. 180), referring to Peter and Paul, similarly asserts, “Now Matthew published a written Gospel among the Hebrews in their own tongue, while Peter and Paul were evangelizing and founding the church in Rome. But after their departure [ἔξοδος; death?], Mark, the disciple and interpreter of Peter, himself also handed over to us, in writing, the things preached by Peter.”7 The implication is that Mark is writing from Rome after the deaths of Peter and Paul.
Clement of Alexandria (c. 180) specifically refers to Rome: “When, by the Spirit, Peter had publicly proclaimed the Gospel in Rome, his many hearers urged Mark, as one who had followed him for years and remembered what was said, to put it all in writing. This he did and gave copies to all who asked. When Peter learned of it, he neither objected nor promoted it.”8Peter’s apparent indifference to Mark’s work suggests that this statement was not created as an apologetic defense of the Petrine tradition, since, if that were the case, one would expect a much more positive affirmation by Peter. Other early church writers, including Tertullian (Marc. 4.5), Origen (Eusebius, Hist. eccl. 6.25.5), and Jerome (Comm. Matt., prologue 6), affirm Mark’s role as author and that he was dependent on the eyewitness accounts of Peter.
How many of these early witnesses are dependent on one another is not known. Yet their unanimity is impressive. No competing claims to authorship are found in the early church. Since John Mark was a relatively obscure figure, it seems unlikely that a gospel would have been attributed to him if he had not in fact written it. We could add to this the evidence of the titles to the Gospels, which, as noted above, appear in nearly all of our extant manuscripts.
Internal evidence for Markan authorship
Although internal evidence does not provide direct evidence for authorship, it can be used to help corroborate the external claims. (1) The author’s many Aramaisms (Mark 3:17; 5:41; 7:11, 34; 10:45; 14:36) are compatible with a Palestinian Jew like John Mark (cf. Acts 12:12). (2) The large number of Latinisms would also fit a Roman provenance (place of origin). (3) The identification of Rufus and Alexander as sons of Simon of Cyrene (15:21) is also significant, since it confirms that the author was known to his readers. It seems unlikely that the title “according to Mark” (κατὰ Μάρκον) could have been attached to the gospel so early if the original readers knew it came from someone else. Furthermore, if this Rufus is the same one mentioned in Rom 16:13, we have incidental confirmation of a Roman provenance.
2) Eusebius, Hist. eccl. 3.39.15 (translation from P. Maier, Eusebius: The Church History (Grand Rapids: Kregel, 1999), 129 – 30. 3)“Papias thus admits that he learned the words of the apostles from their followers but says that he personally heard Aristion and John the presbyter. He often quotes them by name and includes their traditions in his writings” (Eusebius, Hist. eccl. 3.39.7; trans. Maier, Eusebius, 127). 4)The connection to Peter is also indirectly made by Justin Martyr (c. AD 150), who refers to Mark 3:16 – 17 ( Jesus’ naming of Simon as “Peter,” and James and John as “Sons of Thunder”) as coming from the memoirs of Peter (Dial. 106). For strong defenses of the authenticity of the Papias tradition, see Hengel, Studies, 47 – 53; Robert H. Gundry, Mark: A Commentary on His Apology for the Cross (Grand Rapids: Eerdmans, 1993), 1026 – 45. 5)Cited by C. Black, Mark: Images of an Apostolic Interpreter (Columbia, SC: University of South Carolina Press, 1994), 119. The date of the Anti-Marcionite prologues is disputed, with some scholars placing them in the third century. 6)The same description is found in Hippolytus, Haer. 7.30.1 (see Black, Mark, 115 – 18). 7) Ireneaus, Haer. 3.1.1; translation from Black, Mark, 99 – 100. 8) Cited by Eusebius, Hist. eccl. 6.14.6 – 7 (trans. Maier, Eusebius, 218).
Author: Although the Gospel of Mark does not name its author, it is the unanimous testimony of early church fathers that Mark was the author. He was an associate of the Apostle Peter, and evidently his spiritual son (1 Peter 5:13). From Peter he received first-hand information of the events and teachings of the Lord, and preserved the information in written form.
It is generally agreed that Mark is the John Mark of the New Testament (Acts 12:12). His mother was a wealthy and prominent Christian in the Jerusalem church, and probably the church met in her home. Mark joined Paul and Barnabas on their first missionary journey, but not on the second because of a strong disagreement between the two men (Acts 15:37-38). However, near the end of Paul’s life he called for Mark to be with him (2 Timothy 4:11).
Date of Writing: The Gospel of Mark was likely one of the first books written in the New Testament, probably in A.D. 55-59.
Commentary 1
T. France, The Gospel of Mark: A Commentary on the Greek Text, New International Greek Testament Commentary (Grand Rapids, MI; Carlisle: W.B. Eerdmans; Paternoster Press, 2002), 339–341.
34 Mark uses προσκαλέομαι to alert the reader to expect something new or emphatic to be revealed, or some new instruction to be delivered to the disciples (cf. 3:13, 23; 6:7; 7:14; 10:42; 12:43). What is surprising here is that the object of the verb is not just the disciples, whom one would expect, but τὸν ὄχλον σὺν τοῖς μαθηταῖς αὐτοῦ. We have gained from vv. 27–33 the impression that the setting is a private retreat in the countryside in the far north of Palestine, where Jesus was presumably little known and the population probably largely non-Jewish. A crowd of people in this area who were at least potentially followers of Jesus seems incongruous, and they will play no further part in the narrative. From the narrator’s point of view, however, the introduction of the ὄχλος serves here, rather like οἱ περὶ αὐτὸν σὺν τοῖς δώδεκα in 4:10, to widen the audience for a key pronouncement; their inclusion in the audience asserts that the harsh demands of the following verses apply not only to the Twelve but to anyone else who may wish to join the movement. The introductory phrases εἴ τις θέλει and ὃς γὰρ ἐάν (vv. 35, 38) further generalise the scope of the paragraph; this is not a special formula for the elite, but an essential element in discipleship.
ὀπίσω μου is used here not as in v. 33 but in its more normal NT sense (see 1:17, 20 etc.), and the double use alongside it of ἀκολουθέω (cf. 1:18; 2:14) confirms that we have here a basic condition of discipleship. It is to join Jesus on the way to execution. This is the first use of σταυρός by Mark, and neither noun nor verb will occur again before chapter 15. Jesus’ predictions of his death in 8:31; 9:31; 10:33–34 do not spell out the means of death, and this specifically Roman form of execution would not be the first to come to a Jewish mind when hearing of death at the behest of the Jewish authorities. By the time Mark wrote his gospel, of course, Jesus’ crucifixion was well known, and his readers would need no explanation for the σταυρός here. But at the beginning of the journey to Jerusalem such language is calculated to shock, and evokes a vivid and horrifying image of the death march with all its shameful publicity. The preservation of so specific an image at more than one point in the gospel tradition (see also the Q saying Mt. 10:38; Lk. 14:27) may suggest that it originates from Jesus’ own awareness of how he would die rather than from Mark’s reading back the later event.
The metaphor of taking up one’s own cross is not to be domesticated into an exhortation merely to endure hardship patiently. In this context, following 8:31, it is an extension of Jesus’ readiness for death to those who follow him, and the following verses will fill it out still in terms of the loss of life, not merely the acceptance of discomfort. While it may no doubt be legitimately applied to other and lesser aspects of the suffering involved in following Jesus, the primary reference in context must be to the possibility of literal death.
The call to take up the cross is preceded by ἀπαρνησάσθω ἑαυτόν, a phrase not paralleled in the gospel tradition. The verb ἀπαρνέομαι is particularly associated with Peter’s eventual denial not of himself but of his master; in that context it means to dissociate oneself completely from someone, to sever the relationship. So the reflexive use implies perhaps to refuse to be guided by one’s own interests, to surrender control of one’s own destiny. In 2 Tim. 2:13 ἀρνήσασθαι ἑαυτόν (of God as subject) means to act contrary to his own nature, to cease to be God. What Jesus calls for here is thus a radical abandonment of one’s own identity and self-determination, and a call to join the march to the place of execution follows appropriately from this. Such ‘self-denial’ is on a different level altogether from giving up chocolates for Lent. ‘It is not the denial of something to the self, but the denial of the self itself.’
35–37 The talk of losing and gaining the ψυχή in these verses depends on the range of meaning of ψυχή, and poses problems for the translator. The same noun denotes both the ‘being alive’ (as opposed to dead; cf. 3:4; 10:45) which one might seek to preserve by escaping persecution and martyrdom, and the ‘real life’ which may be the outcome of such martyrdom, and therefore is to be found beyond earthly life. It is in this latter sense that the English word ‘soul’ is traditionally used here, but the wordplay is better preserved by retaining ‘life’ but where necessary qualifying it with ‘true/eternal’ or ‘earthly’.
The immediate subject of these verses, following as they do the imagery of taking up one’s cross in v. 34, is surely the literal loss of (earthly) life which the disciple is called to accept as a potential result of following Jesus. Only that sense fully does justice to the wordplay. To extend this sense to the loss of privilege, advantage, reputation, comfort, and the like may be legitimate in principle, but only so long as this primary and more radical sense is not set aside. To cling to the things of this life, the things which humanity naturally values most, is the way to forfeit true life; clinging to life itself is the ultimate example of this concern, and is set in contrast with the acceptance of death (for the right reason) as the way to real life. Jesus himself, in his death and resurrection, will be the supreme example of this new perspective.
The promise of true life is not attached to death in itself, but to the loss of life ἕνεκεν [ἐμοῦ καὶ] τοῦ εὐαγγελίου (see Textual Note). The possibility of literal martyrdom as the outcome of Christian discipleship is clearly envisaged here; cf. 13:9 (ἕνεκεν ἐμοῦ). Jesus’ expectation of his own death must have raised this possibility, and the experiences of the early church from Acts 7 onwards would add weight to it. The specific mention of the εὐαγγέλιον as the cause of loss of life indicates that the disciples are to play an active role in mission rather than merely privately following the teaching of Jesus, and that it is in this missionary work that they are likely to meet with persecution and death. Best rightly emphasises that the addition of this phrase indicates the inadequacy of a view of discipleship as merely the imitation of Jesus.
In the Synoptic Gospels κόσμος does not carry the negative connotation it has elsewhere in the NT, and especially in John; it denotes the created world in a neutral sense. κερδῆσαι τὸν κόσμον ὅλον therefore simply expresses the height of human ambition and achievement, measured in terms of earthly life. While ζημιόω sometimes carries a juridical sense of penalty or punishment, the context here does not require that nuance. Its more normal sense is simply loss or disadvantage. ζημιωθῆναι in v. 36 therefore denotes the opposite of κερδῆσαι; this is a profit and loss account, and it is clearly understood that the loss of the ψυχή (here ‘true life’) far outweighs any gain in terms of earthly advantage.
The same idea is differently expressed in the rhetorical question of v. 37, where again the assumption is made that the ψυχή is all that ultimately matters, and that nothing else can compensate for its loss. The ἀντάλλαγμα (cf. LXX Job 28:15) is the ‘exchange rate’ at which the ψυχή is valued; it is beyond price. The language of exchange echoes Ps. 49:7–9 (though LXX there uses λυτρόω/λύτρωσις, not ἀνταλλάσσομαι/ἀντάλλαγμα), but whereas the psalm speaks of a payment to avoid physical death, here the focus has moved to ‘true life’, which is even more beyond the reach of human valuation. There is no reason in this context to read into the question any developed theology of redemption; it is simply a statement of comparative value.
Commentary 2
David Smith, Mark: A Commentary for Bible Students (Indianapolis, IN: Wesleyan Publishing House, 2007), 157–169
Insight into the Messiah’s Task
Mark 8:[31]–33
…….3. Jesus’ First Passion Prediction 8:31–33
Coupled with the immediately preceding command to silence, the core of Jesus’ self-revelation began with a redirection of the disciples’ choice of titles. They chose Messiah; Jesus offered another, more enigmatic title: the Son of Man (8:31). What Jesus was about to say regarding suffering and death might have been incomprehensible if He had retained the disciples’ more victorious-sounding title: “Christ.” Jesus would not allow himself to be categorized. For Jesus, the title “Christ” carried too much militaristic and nationalistic baggage; it had to be tempered with the less familiar “Son of Man” designation. He went on to teach His disciples the essential issues with reference to His identity.
The “Son of Man must suffer many things” (8:31). The disciples had seen nothing but power and victory in the acts of Jesus thus far. So these words had no place to take root. Moreover, the suffering and death of the Messiah raised huge theological problems. If Jesus was indeed the Messiah, why would God allow Him to be rejected and be killed (8:31)? Though the answer is not fully elucidated in the gospel of Mark, it is part of a plan found in the Old Testament. Mark reported that the Son of Man must suffer many things. The word must is often used of divine necessity as spelled out later in 9:12 and 14:21, 49. Thus, Jesus’ rejection and death are to find their source in Scripture and the heart of the Father’s will and not in the violence of Palestinian politics. Mark would not allow Jesus’ death to be read as a sociological mistake but rather as an act of divine redemption.
The wording of each of the three passion predictions is just a bit different. It is only in this passage that the reader of Mark sees the word suffer. But with rejected, Mark draws attention to Psalm 118:22, where Christians identify in Jesus’ fate that the “stone the builders rejected has become the capstone” and His following vindication. Each of the three passion predictions ends with the same climax: the resurrection of Jesus from the dead. The disciples were no more attentive to this aspect of Jesus’ teaching than any other.
No matter how much explanation He provided, the disciples never achieved complete clarity. This unveiling of the messianic mission demanded a response from the disciples. And it came from Peter as he took [Jesus] aside and began to rebuke him (8:32). Peter displayed that he was at cross-purposes with Jesus’ agenda. The word “rebuke” connotes a command by one taking authority over another. Jesus, without hesitation, turned and looked at his disciples (8:33), implicating them as coconspirators, as he rebuked Peter. The repetition of the same verb (8:31, command of Jesus to disciples; 8:32, Peter’s rebuke of Jesus; 8:33, Jesus’ rebuke to Peter) demonstrates irreconcilable perspectives. Jesus settled the issue when He ordered Peter to get behind Him. Note how this short statement is spatially as well as relationally oriented. First, Jesus said, “Get behind me.” This is the same language used by Jesus in His initial call of His disciples in 1:17 and could be translated, “Come, behind Me.” This might be understood as Jesus calling Peter to get back in step with Him. Further, there is another occurrence of the word in the next verse, where the phrase is translated, “If anyone would come after me” (8:34), cementing Peter’s call to follower-ship based not on his notion of power or might, but on Jesus’ revelation of rejection, shame, and death.
Relationally, Jesus called Peter “Satan.” In short order, Jesus completed His own counter-rebuke of Peter. Peter’s plan, which avoided the cross, placed him in league with Jesus’ archenemy. This is partially why Jesus commanded (rebukes) the disciples to silence, for the proclamation of a Messiah without the cross is satanic in its message. This exchange was brought to a culmination with Jesus’ closing reproof: “You do not have in mind the things of God, but the things of men” (8:33). The NIV makes this a separate sentence, while in actuality it is a dependent clause, specifically a result clause: “for you do not have in mind the things of God but the things of people.” The plain teaching of Jesus (8:31) cannot be grasped on a merely human level.
The vision for ministry that Jesus is teaching is irreconcilable with the vision Peter and the other disciples have for Him as the Messiah. The misguided vision of the disciples and their determined refusal to adopt Jesus’ revelation precludes them from full comprehension. Teaching, even from such a skilled educator as Jesus, would not adequately overcome humanity’s blindness. Thus, Mark conveys a truth that became Christian doctrine: Men and women must not merely become educated (or catechized) in the Church; they must initially be transformed.
The Demands of Discipleship
Mark 8:34–9:1
The Cost of Following Jesus 8:34–35
The call to discipleship is comprehensive in its reach (disciples and crowds), but it immediately takes on a conditional nature: “If anyone would come after me” (8:34). The phrase literally translated reads, “If someone wishes/wants after me to follow.…” Jesus demands a heartfelt choice, which eliminates other, possibly more appealing, choices.
Jesus set the agenda according to His spiritual compass; a follower must “deny himself.” Powerfully, the insertion of the reflexive pronoun himself implies the first aspect of discipleship is to refuse to be guided by one’s own interests. Moreover, self-denial is not to be confused with asceticism (the denial of things one desires) or even with self-discipline. Self-denial is the denial of the self itself (see Phil. 2:3–4). The second requirement of a follower is to “take up his cross.” This is the first use of the word in the Gospel, certainly creating a link back to Jesus’ earlier prediction of His own death. In the first century, a cross indicated punishment of a shamed criminal at the hands of the Romans. Moreover, this Roman form of execution might be heard by the listeners as a call to rebel against Rome and to risk their lives. Yet, the word will not reoccur until chapter 15. This provided Jesus with ample time to define the impact and meaning of His own death and the cross-bearing imagery associated with His followers. For in summary, the self-denial to which Jesus calls one is abandonment of one’s autonomy and adoption of Jesus’ leadership and lordship.
Finally, Jesus beckoned His disciples to “follow me” (8:34). Jesus’ initial thrust into discipleship-making seems more directional than doctrinal. His call is bracketed with terms of motion. “Mark is rich in verbs of motion. Jesus is on the move; he summons disciples to come after him” Each time Jesus called His disciples, He was in motion (1:16, 19; 2:14; 10:17). Further, His call was to get in step directly behind Him. Thus, for one to be a disciple, one must follow. The mark of a faithful disciple is to be seen not in fully comprehending all the theological nuances of the person of Jesus, but in setting one’s sight unwaveringly on the path laid out by Jesus. The path to the cross is costly and counterintuitive, yet Jesus clearly laid out the directional markers for all who are willing to follow.
The demands of discipleship are further refined. “For whoever wants to save his life will lose it, but whoever loses his life for me and for the gospel will save it” (8:35). Jesus offered this paradoxical principle for savings one’s life, using two meanings of “life.” The word implies physical life in its first use (as opposed to death; see 3:4; 10:45). In this sense, people might think they can preserve their lives by avoiding conflict and persecution. However, Jesus’ other meaning was that by losing one’s physical life, one receives (saves) eternal life. More precisely, this call to a loss of life is not a morbid acceptance of death. Rather, it is an adoption of Jesus (for me) and His mission agenda (for the gospel) around which one reorients one’s focus and through which one discovers true life. A disciple is to follow Jesus by publicly adhering to the gospel, proclaiming it to the world, and dying if necessary.
Keeping an Eternal Perspective 8:36–9:1
“What good is it for a man to gain the whole world, yet forfeit his soul?” (8:36). Here the contrast between this world and the next (soul) is made more explicit. In this Gospel, “world” represents the created order in a neutral sense. Gain implies human ambition and drive for worldly success. Thus, one should not connote an evil intent on the part of the pursuer, but the explicit contrast as the loss of one’s life or soul far exceeds any profit in terms of earthly gain. This contrast is continued in the rhetorical question “Or what can a man give in exchange for his soul?” (8:37). This passage continues with the theme that we cannot grasp the priceless value of one life or soul, and that there is another way to categorize value apart from what we can see, hear, smell, touch, and taste.
Verse 38 repeats the conditional emphasis begun in 8:34: “If anyone is ashamed of me and my words in this adulterous and sinful generation, the Son of Man will be ashamed of him when he comes in his Father’s glory with the holy angels.” The contrast of honor and shame was a primary value of the first century. So, if anyone was ashamed of Jesus (of me) and His authoritative demands (and my words), she or he might have received worldly honor, but forfeited honor in the future, coming Kingdom. David Garland summarizes it this way:
Jesus uses the threat of judgment to induce his followers to be faithful. To be put to shame is the opposite of vindication (Ps. 25:3; 119:6; Isa. 41:10–11; Jer. 17:18). Those who may be frightened by the edicts of earthly courts (represented in the Gospel by Herod Antipas, the high priest’s Sanhedrin, and the Roman governor, Pilate) should fear even more the decision of the heavenly tribunal, which determines their eternal destiny.
The use of the adjective adulterous reminds the reader of the frequent Old Testament charges against the nation of Israel as she constantly committed spiritual adultery and went out after other gods (Isa. 1:4, 21; Ezek. 16:32; Hos. 2:4).
The traditional early church understanding of the Son of Man “coming” was that of the parousia or the second coming. Yet the imagery and background in this material comes from the visions of Daniel 7: “… one like a son of man, coming with the clouds of heaven.” He is presented before the throne of the Ancient of Days (Dan. 7:13–14), and “He was given authority, glory and sovereign power; all peoples, nations and men of every language worshiped him. His dominion is an everlasting dominion that will not pass away, and his kingdom is one that will never be destroyed.” The scene is clearly set in heaven, and His “coming” is better described as an entrance into the throne room of God, not the “second coming” to earth. One must keep in mind that Jesus’ teaching in 8:31 is an intricate series of contrasts between this world and the next, with the Son of Man prophecy as its climax. Thus, the shaming of the Son of Man on earth by people will result in their judgment in the heavenly realm.
There is an interesting combination of Son of Man language and the Father’s glory. The voice at Jesus’ baptism directly referred to Jesus as His Son (1:11). Jesus only referred to God as His Father again in 13:23 and in His prayer in Gethsemane (14:36). Yet the importance is not simply familial but theological. For here the Son of Man and Son of God concepts are closely linked with each other and with the messianic overtones of the entire passage. This would not happen again until Jesus’ confession before the high priest in 14:62.
And he said to them, “I tell you the truth, some who are standing here will not taste death before they see the kingdom of God come with power” (9:1). Seemingly, 9:1 assures the first-century disciples (and subsequent readers) that for all they abandon in this lifetime, they will indeed see the kingdom of God come and share in His exaltation. The implication is that the event being referred to is near enough that a privileged few will catch a glimpse of this unveiling. Numerous suggestions have been offered regarding the fulfillment of Jesus’ prediction. The most prominent suggestions include (1) the death of Jesus and the resultant tearing of the Temple curtain, (2) victory over death in His resurrection, (3) His ascension and enthronement in heaven, (4) the coming of the Holy Spirit at Pentecost, and (5) the destruction of Jerusalem in a.d. 70. All of these would certainly be viable options within the lifetime of the original hearers. Yet nearly all except the first option fall outside the narrative of the gospel of Mark. Possibly the most text-centered line of interpretation would be to look forward to the Transfiguration (9:2–13). The events are linked temporally and precisely—after six days—a highly unusual practice for Mark outside of the passion narrative. Additionally, the Transfiguration narrative reports what the disciples saw, and the cloud appearing and enveloping the disciples is suggestive of the Mount Sinai theophany (Exod. 19), leaving the reader with the impression of Jesus coming in power. One could feel less than satisfied with seeing Jesus transfigured on a mountain being equated with seeing the kingdom of God come with power. Yet throughout the Gospel of Mark, the kingdom of God and the person of Jesus are inseparably linked. The Kingdom was brought near with the coming of Jesus and the proclaiming of the good news of God (1:14–15). Later, the secret of the Kingdom was revealed in Jesus’ parabolic instruction (4:10–12). Thus, it seems appropriate for Mark to make known the joining of the Kingdom of God and the person of Jesus as a signal of the real, though not yet fully revealed, presence.
Experts now say the COVID lockdowns and school shutdowns went too far. A new report from the CDC claims 1 in 3 teen girls are suicidal. Could these issues be related? It’s no surprise to Dennis. After all, he always said, “the lockdowns are the greatest mistake in human history.” Experts at the CDC have advice for how to treat this mental health crisis, but should we listen to them or have they lost credibility?
Alternatives to terms like “male” and “female” and “mother” and “father” should be sought in science because they assume that sex is binary and heterosexuality is the norm, a group of researchers from the US and Canada suggests.
Male and female should instead be referred to as “sperm-producing” and “egg-producing,” the Ecology and Evolutionary Biology (EEB) Language Project said, according to the Times of London.
Meanwhile, father and mother should be labeled “parent,” “egg donor” and “sperm donor” in the scientific field.
The group has called on the scientific field to use words that are more “inclusive and precise,” according to a press release from the University of British Columbia, which has three researchers in the initiative.
“Much of Western science is rooted in colonialism, white supremacy and patriarchy, and these power structures continue to permeate our scientific culture,” some project members wrote in the Trends in Ecology and Evolution journal….
…The offending words include terms as basic as “male” and “female”, which the EBB Language Project wants to replace with supposedly more inclusive terms like “sperm-producing”, “egg producing”, and “XY/XX individual”.
“The only possible response is contemptuous ridicule,” the notorious atheist — or “anti-theist” — told The Telegraph
“I shall continue to use every one of the prohibited words. I am a professional user of the English language. It is my native language,” he vowed.
“I am not going to be told by some teenage version of Mrs Grundy which words of my native language I may or may not use,” he added, referring to a stock character in British discourse dating from the late 1700s, characterised by a tendency to censorious priggishness…..
TO WIT:
Bad ideas are everywhere, spreading like viruses. Ironically, the antidote is readily available. We just have to have the courage to use it. Seth Dillon, CEO of The Babylon Bee, provides the prescription.
More via Black Conservative Perspective
BASED Transman Sets The ABC Community Straight On Biology And Not Calling Women ‘CIS’




 This is a version based off of my hand-out I passed out teaching an adult Sunday class to at church. More media driven posts of mine using it are here:
This is a version based off of my hand-out I passed out teaching an adult Sunday class to at church. More media driven posts of mine using it are here: